來源:量子位
就在剛剛,李飛飛空間智能首個項目突然發布:
僅憑借1張圖,就能生成一個3D遊戲世界的AI系統!
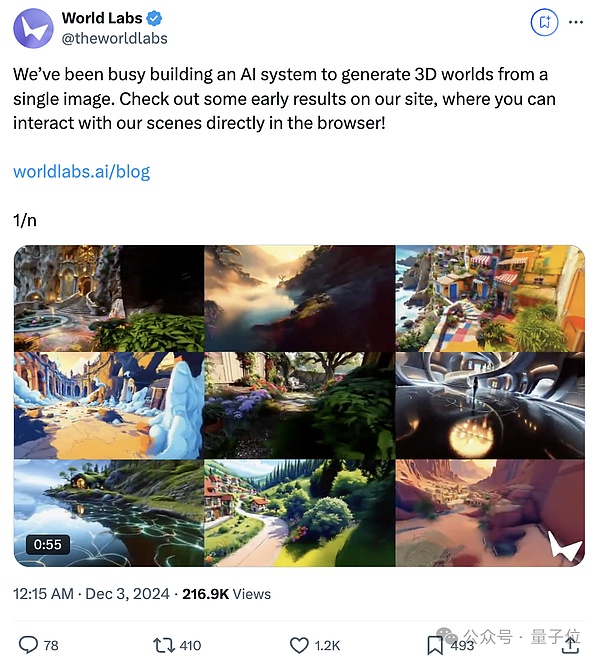
重點在於,生成的3D世界具有交互性。
能夠像玩遊戲那樣,自由地移動相機來探索這個3D世界,淺景深、希區柯克變焦等操作均可行。

隨便輸入一張圖:

除了這張圖本體,可探索的3D世界裏,所有東西都是AI生成的:

這些場景在瀏覽器中實時渲染,配備了可控的攝像機效果和可調節的模擬景深(DoF)。

你甚至可以改變其中物體顏色,動態調整背景光影,在場景中插入其他對象。



此外,之前大多數生成模型預測的是像素,而這個AI系統直接預測3D場景。
所以場景在你移开視线再回來時不會發生變化,並且遵循基本的3D幾何物理規則。
網友們直接炸开鍋,評論區“難以置信”一詞直接刷屏。
其中不乏Shopify創始人Tobi Lutke等知名人士點贊:
還有不少網友認爲這直接爲VR打开了新世界。

官方則表示“這僅僅是3D原生生成AI未來的一個縮影”:
我們正在努力盡快將這項技術交到用戶手中!
李飛飛本人也第一時間分享了這項成果並表示:
無論怎么理論化這個想法,用語言很難描述通過一張照片或一句話生成的3D場景互動的體驗,希望大家喜歡。
目前候補名單申請已开啓,有內容創作者已經用上了。
羨慕的口水不爭氣地從眼角落了下來。
官方博文表示,今天,World labs邁出了通往空間智能的第一步:
發布一個從單張圖片生成3D世界的AI系統。
Beyond the input image, all is generated。
而且是輸入任何圖片。
而且是能夠互動的3D世界——用戶可以通過W/A/S/D鍵來控制上下左右視角,或者用鼠標拖動畫面來逛這個生成的世界。
官網博文中放了很多個可以試玩的demo。
這次真的推薦大家都去試玩一下,上手體驗和看視頻or動圖的感受非常的不一樣。
(直通車按慣例,放在文末)

好,問題來了,這個AI系統生成的3D世界還有什么值得探究的細節之處?
攝影機效果
World Labs表示,一旦生成,這個3D世界就會在瀏覽器中實時渲染,給人的感覺跟在看一個虛擬攝像頭似的。
而且,用戶能夠精准地控制這個攝像頭。
所謂“精准控制”,有2種玩法,
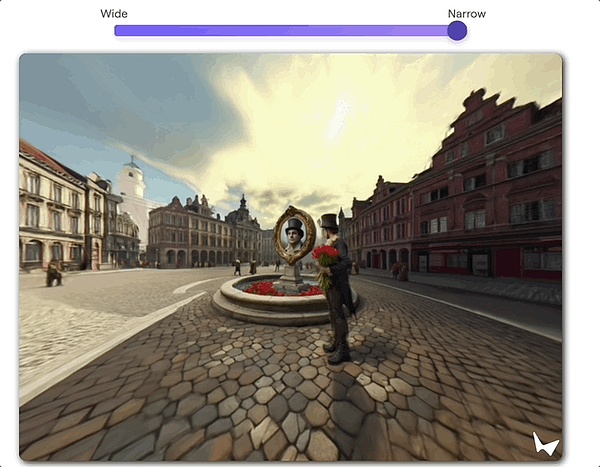
一是能夠模擬景深效果,也就是只能清晰對焦距離相機一定距離的物體。

二是能模擬滑動變焦(Dolly Zoom),也就是電影拍攝技巧中非常經典的希區柯克變焦。
它的特點是“鏡頭中的主體大小不變,而背景大小改變”。
很多驢友去西藏、新疆玩兒的時候都希望用希區柯克變焦拍視頻,有很強的視覺衝擊力。
在World Labs展示中,效果如下(不過在這個玩法裏,沒辦法控制視角):
3D效果
World Labs表示,大多數生成模型預測的都是像素,與它們不同,咱這個AI預測的是3D場景。
官方博文羅列了三點好處:
第一,持久現實。
一旦生成一個世界,它就會一直存在。
不會因爲你看向別的視角,再看回來,原視角的場景就會改變了。
第二,實時控制。
生成場景後,用戶可以通過鍵盤或鼠標控制,實時在這個3D世界暢遊移動。
你甚至可以仔細觀察一朵花的細節,或者在某個地方暗中觀察,用上帝視角注意這個世界的一舉一動。
第三,遵循正確的幾何規則。
這個AI系統生成的世界,是遵守3D集合物理基本規則的。
某些AI生成的視頻,雖然效果很夢核,但可沒有咱的這種深度的真實感喲(doge)。
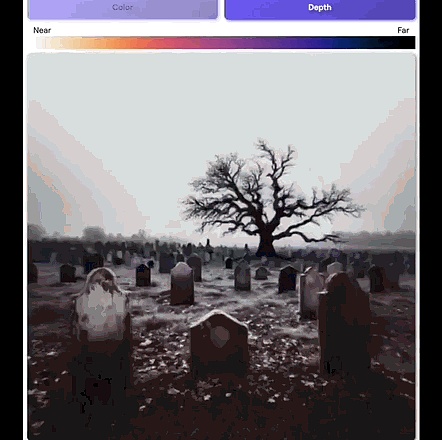
官方博文中還寫道,創造一個可視化3D場景,最簡單的辦法是繪制深度圖。
圖中每個像素的顏色,都是由它和攝像頭的距離來決定的。
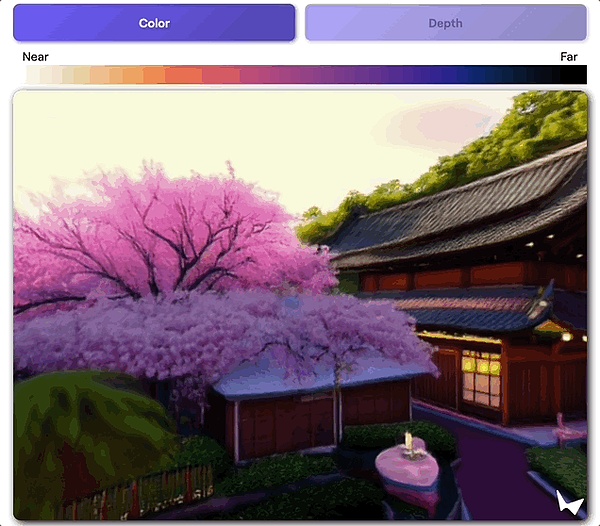
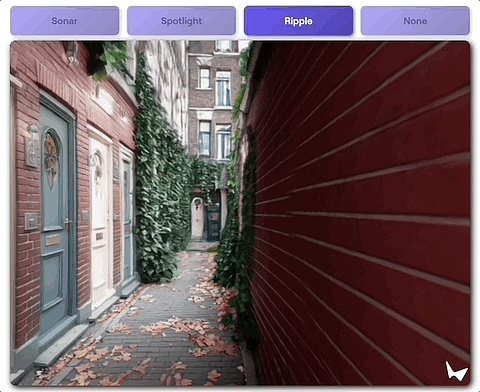
當然了,用戶可以使用3D場景結構來構建互動效果——
單擊就能與場景互了,包括但不限於突然給場景打個聚光燈。
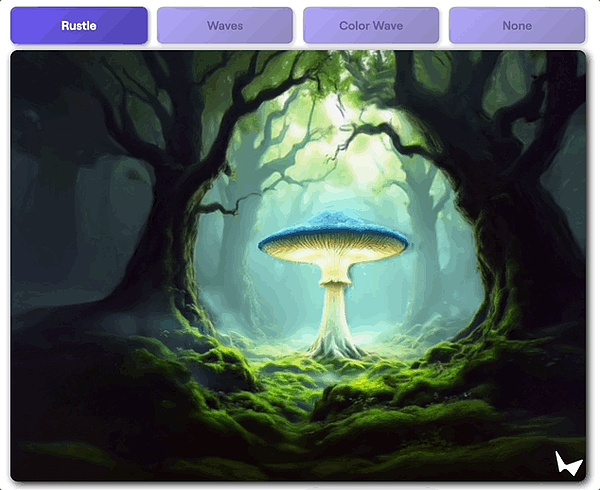
動畫效果?
那也是so easy啦。
走進繪畫世界
團隊還玩兒了一把,以“全新的方式”體驗一些經典的藝術作品。
全新,不僅在於可互動的交互方式,還在於就靠輸入進去的那一張圖,就能補全原畫裏沒有的部分。
然後變成3D世界。
這是梵高的《夜晚露天咖啡座》:

這是愛德華·霍普的《夜行者》:

創造性的工作流
團隊表示,3D世界生成可以非常自然地和其它AI工具相結合。
這讓創作者們可以用他們已經用順手的工具感受新的工作流體驗。
舉個慄子:
可以先用文生圖模型,從文本世界來到圖像世界。
因爲不同模型有各自擅長的風格特點,3D世界可以把這些風格遷徙、繼承過來。
在同一prompt下,輸入不同風格的文生圖模型生成的圖片,可以誕生不同的3D世界:
一個充滿活力的卡通風格青少年臥室,牀上鋪着五彩斑斕的毯子,桌子上雜亂地擺放着電腦,牆上掛着海報,散落着運動器材。一把吉他靠在牆上,中間鋪着一塊舒適的花紋地毯。窗戶透進的光线給房間增添了一絲溫暖和青春的氣息。
World Labs和空間智能
“World Labs”公司,由斯坦福大學教授、AI教母李飛飛在今年4月創立。
這也是她被曝出的首次創業。
而她的創業方向是一個新概念——空間智能,即:
視覺化爲洞察;看見成爲理解;理解導致行動。
在李飛飛看來,這是“解決人工智能難題的關鍵拼圖”。
只用了3個月時間,公司就突破了10億美元估值,成爲新晉獨角獸。
公开資料顯示,a16z、NEA和Radical Ventures是領投方,Adobe、AMD、Databricks,以及老黃的英偉達也都在投資者之列。
個人投資者中也不乏大佬:Karpathy、Jeff Dean、Hinton……
今年5月,李飛飛有一場公开的15分鐘TED演講。
她洋洋灑灑,分享了對於空間智能的更多思考,要點包括:
視覺能力被認爲引發了寒武紀大爆發——一個動物物種大量進入化石記錄的時期。最初是被動體驗,簡單讓光线進入的定位,很快變得更加主動,神經系統开始進化……這些變化催生了智能。
多年來,我一直在說拍照和理解不是一回事。今天,我想再補充一點:僅僅看是不夠的。看,是爲了行動和學習。
如果我們想讓AI超越當前能力,我們不僅想要能夠看到和說話的AI,我們還想要能夠行動的AI。空間智能的最新裏程碑是,教計算機看到、學習、行動,並學習看到和行動得更好。
隨着空間智能的加速進步,一個新時代在這個良性循環中正在我們眼前展开。這種循環正在催化機器人學習,這是任何需要理解和與3D世界互動的具身智能系統的關鍵組成部分。
據報道,該公司的目標客戶包括視頻遊戲开發商和電影制片廠。除了互動場景之外,World Labs還計劃开發一些對藝術家、設計師、开發人員、電影制作人和工程師等專業人士有用的工具。
如今伴隨着空間智能首個項目的發布,他們要做的事也逐漸具象化了起來。
但World Labs表示,目前發布的只是一個“早期預覽”:
我們正在努力改進我們生成的世界的規模和逼真度,並嘗試新的方式讓用戶與之互動。
參考鏈接:
[1]https://www.worldlabs.ai/blog
[2]https://mp.weixin.qq.com/s/3MWUv3Qs7l-Eg9A9_3SnOA?token=965382502&lang=zh_CN
[3]https://x.com/theworldlabs/status/1863617989549109328
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。