 免責聲明: 內容不構成买賣依據,投資有風險,入市需謹慎!
免責聲明: 內容不構成买賣依據,投資有風險,入市需謹慎!
英偉達官宣下一代最強AI芯片 GPU性能8年提高1053倍

 元宇宙之心
企業專欄
剛剛
元宇宙之心
企業專欄
剛剛
 關注
關注
在當今計算、網絡和圖形技術的發展歷史上,英偉達有許多獨特之處。其中之一就是,它現在手頭資金雄厚,而且憑借其架構、工程設計和供應鏈,在人工智能生成市場上佔據了領先地位。因此,英偉達可以隨心所欲地規劃未來的發展路线圖,只要有助於推動技術進步。
早在2000年代,英偉達就已經是一家非常成功的創新企業,實際上並不需要涉足數據中心計算領域。但是,高性能計算(HPC)研究人員將英偉達拉入了加速計算領域,然後人工智能研究人員利用GPU計算優勢,創造了一個全新的市場,這個市場已經等待了四十年,等待着以合理的價格將大量計算與海量數據相碰撞,真正實現把類似“思維機器”的東西帶進到日常生活中。
致敬Danny Hillis、Marvin Minsky和Sheryl Handler,他們在1980年代創立了Thinking Machines,試圖爲AI處理提供支持,而不是傳統的HPC模擬和建模應用。
同樣,Yann LeCun在AT&T貝爾實驗室創造卷積神經網絡時,既沒有數據也沒有計算能力來制造我們現在所知的人工智能。
當時,黃仁勳是LSI Logic公司的主管,該公司生產存儲芯片,黃仁勳最終成爲AMD公司的CPU設計師。20世紀90年代初,就在Thinking Machines正處於艱難時期(最終破產),黃仁勳與Chris Malachowsky和Curtis Priem在聖何塞東邊的Denny's餐廳會面,並創立了Nvidia。
Nvidia從超級分頻器領域看到了新興的人工智能機遇,並开始構建系統軟件和底層大規模並行硬件,以實現人工智能革命的夢想。
這一直是計算的終極狀態,也一直是我們所邁向的奇點。
如果其他星球上存在生命,那么生命總會進化到擁有大規模殺傷性武器的地步,總會創造出人工智能。可能也是在同一時間。在那一刻之後,這個世界會如何處理這兩種技術,才是決定其能否在大滅絕事件中幸存下來的關鍵。
這聽起來不像是討論芯片制造商路线圖的正常开場白。但事實並非如此,這是因爲我們生活在一個充滿變革的時代。
在台灣台北舉行的年度電腦展(Computex)上,Nvidia的聯合創始人兼首席執行官黃仁勳在其主題演講中,再次試圖將生成式人工智能革命(他稱之爲“第二次工業革命”)置於其背景之下,並展示了AI的未來,尤其是英偉達硬件的未來。
由此,我們窺見了GPU和互聯技術路线圖。但是據我們所知,這並不是計劃的一部分,黃仁勳和他的主題演講通常都是最後一刻才真正开始。
01.革命不可避免
黃博士提醒我們注意:生成式人工智能的核心在於規模。同時也指出2022年底ChatGPT時刻的到來既有技術方面的原因,也有經濟方面的原因。
要達到ChatGPT的突破性時刻,需要GPU性能的大幅增長,然後再加上大量的GPU。
Nvidia確實實現了性能,這對人工智能的訓練和推理都很重要,而且重要的是,它還從根本上減少了生成作爲大型語言模型響應一部分的標記所需的能量。我們來看一下:
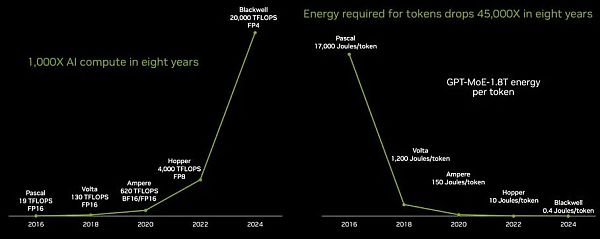
在八年間,從“Pascal P100 GPU”到“Blackwell B100 GPU”,GPU的性能提高了1053倍。其中部分性能是通過降低浮點精度實現的,例如從Pascal P100、Volta V100和Ampere A100 GPU的FP16格式到Blackwell B100使用的FP4格式,降低了4倍。
由於在數據格式、軟件處理和硬件方面運用了大量的數學魔法,如果不降低精度,性能提升將只有263倍,而降低精度不會對LLM性能造成實質性損害。要知道,在CPU市場上,每時鐘核心性能提高10%至15%,核心數量增加25%至30%已屬正常。如果升級周期爲兩年,那么在同樣的八年時間裏,CPU吞吐量將提高4至5倍。
如上圖所示,單位功耗的降低是一個關鍵指標,因爲如果無法爲系統供電,就無法使用系統。而token的能耗成本必須降低,這意味着爲LLM生成的每個token的能耗必須比性能提升的速度更快。
在黃仁勳的主題演講中,爲了給大家提供一些更深層次的背景信息,在Pascal P100 GPU上生成一個token所需的17000焦耳熱量大約相當於兩個燈泡運行兩天,而平均每個字需要三個token。
因此,現在我們开始明白爲什么八年前的LLM甚至不可能在一定規模上運行,使其在執行任務時表現出色了。下圖是在1.8萬億個參數、8萬億個通證數據驅動模型的情況下,訓練GPT-4 Mixture of Experts LLM所需的功率:

對於一個P100集群來說,超過1000千兆瓦時的電量實在是太大了。
黃仁勳解釋道:有了Blackwell GPU,公司將能夠在大約10天內通過大約1萬個GPU來訓練GPT-4 1.8T MoE模型。
如果人工智能研究人員和Nvidia沒有轉向更低精度,那么在這八年時間裏,性能提升也不過是250倍。
降低能源成本是一回事,降低系統成本又是另一回事。在傳統的摩爾定律末期,晶體管每隔18到24個月就會縮小一次,芯片變得越來越便宜、越來越小,這兩種技巧都非常困難。
現在,計算復合體已經達到了微粒極限,每個晶體管都越來越昂貴,因此,由晶體管制成的設備本身也越來越昂貴。HBM內存是成本的重要組成部分,先進的封裝也是如此。
黃仁勳本人今年早些時候在接受CNBC採訪時就曾說過Blackwell的價格。在SXM系列GPU插座中(不包括PCI-Express版本的GPU),P100推出時的成本約爲5000美元;V100約爲1萬美元;A100約爲1.5萬美元;H100約爲2.5萬至3萬美元。B100的成本預計在3.5萬美元到4萬美元之間。
黃仁勳沒有說明的是,運行GPT-4 1.8T MoE基准每一代需要多少GPU,以及這些GPU或運行所需的電費是多少。
下圖這個電子表格顯示,根據黃仁勳所說,大約需要1萬個B100,才能在十天左右的時間內訓練出GPT-4 1.8T MoE:
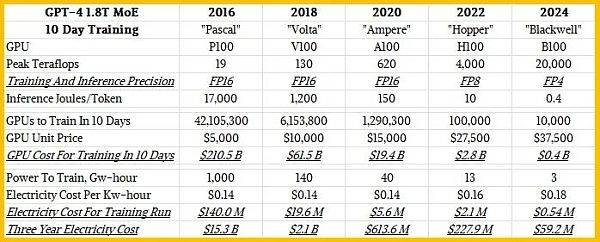
在這八年裏,GPU的價格上漲了7.5倍,但性能卻提高了1000多倍。因此,現在使用Blackwell系統,可以在十天左右的時間內實際訓練出像GPT-4這樣擁有1.8萬億個參數的大型模型,而在兩年前,即使是在Hopper一代剛剛起步的時候,也很難在數月內訓練出擁有數千億個參數的模型。
現在,系統成本將與該系統兩年的電費相當。GPU大約佔人工智能訓練系統成本的一半,因此購买一個1萬個GPU的Blackwell系統大約需要8億美元,而運行十天的電費大約需要54萬美元。
如果購买更少的GPU,就可以減少每天、每周或每月的電費支出,但同時也會相應增加訓練時間,使電費支出再次上升。
就是這樣,即使Hopper H100 GPU平台是“史上最成功的數據中心處理器”,正如黃仁勳在Computex主題演講中所說的那樣,Nvidia仍需繼續努力。
如果將Hopper/Blackwell的投資周期與六十年前IBM System/360的發布相比較,IBM在那次發布中下了至今仍是公司歷史上最大的賭注。
1961年,當IBM开始其“下一代產品线”研發項目時,它是一家年收入22億美元的公司,在整個20世紀60年代,它花費了50多億美元。
Big Blue是華爾街第一家藍籌股公司,正是因爲它花費了兩年的收入和二十年的利潤來創造System/360。它的某些部分推出較晚,表現不佳,但它徹底改變了企業數據處理的本質。
20世紀60年代末,IBM認爲自己可能會創造600億美元的銷售額,但他們創造了1390億美元的銷售額,利潤約爲520億美元。
可以說,Nvidia爲數據中心計算的第二階段掀起了更大的浪潮。
02.抵制是徒勞的
無論是Nvidia還是其競爭對手或客戶,都無法抵擋未來的引力,也無法抵擋生成式人工智能對利潤和生產力的承諾。
因此,Nvidia必將加快步伐,推陳出新。憑借250億美元的銀行存款和今年預計超過1000億美元的收入,或許還有500億美元將進入銀行,它有能力推陳出新,把我們所有人都拉進未來。
黃仁勳表示:“在這個令人難以置信的增長時期,我們要確保繼續提高性能,繼續降低成本,如訓練成本、推理成本等,並繼續擴展人工智能能力,讓每家公司都能擁抱人工智能。我們把性能推得越高,成本下降得就越厲害。”
正如我們上面的表格所清楚顯示的那樣,事實的確如此。這就引出了最新的Nvidia平台路线圖:
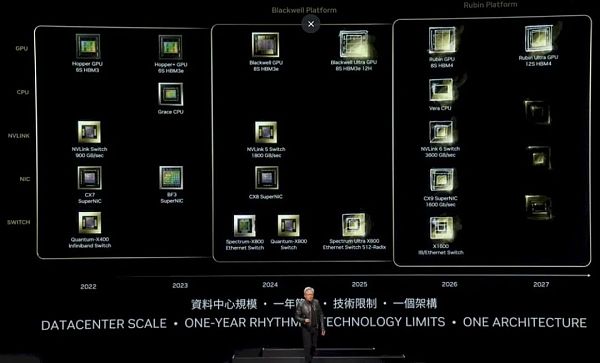
在Hopper這一代中,最初的H100於2022年推出,配備了六層HBM3內存堆棧,通過帶有900 GB/s端口的NVSwitch連接,並配有400 Gb/s端口的Quantum X400(以前稱爲Quantum-2)InfiniBand交換機以及ConnectX-7網絡接口卡。
2023年,H200升級到六層更高容量和帶寬更高的HBM3E內存,從而提升了H200封裝中底層H100 GPU的有效性能。BlueField 3網卡也問世了,它爲網卡增加了Arm內核,使其可以進行輔助工作。
在2024年,Blackwell GPU當然已經推出了8堆HBM3e內存,並與配備1.8TB/sec端口的NVSwitch 5和800Gb/sec的ConnectX-8網卡,以及配備800GB/sec端口的Spectrum-X800和Quantum-X800交換機搭配使用。
現在我們可以看到,在2025年,B200(上圖中稱爲Blackwell Ultra)將擁有8個堆棧的HBM3e內存,這些堆棧有12個芯片高。
據推測,B100中的堆棧有8層高,因此Blackwell Ultra的HBM內存容量至少增加了50%,根據所使用的DRAM容量,增幅可能更大,HBM3E顯存的時鐘速度也可能更高。
Nvidia對Blackwell系列的內存容量含糊其辭,但我們在3月份的Blackwell發布會上估計,B100將擁有192GB內存和8TB/秒的帶寬。
對於未來的Blackwell Ultra,我們預計會有更快的內存出現,如果出現帶寬爲9.6TB/秒的288GB內存,我們也不會感到驚訝。
我們認爲,Ultra變體在SM上的良品率有可能會有所提高,從而使其性能略高於非Ultra前代產品。這將取決於產量。
Nvidia還將在2025年推出弧度更高的Spectrum-X800以太網交換機,可能會在盒子裏裝上六個ASIC,以創建一個非阻塞架構,就像其他交換機常用的那樣,將總帶寬翻倍,從而將每個端口的帶寬或交換機中端口的數量翻倍。

在2026年,我們看到了“Rubin R100 GPU”,在去年發布的Nvidia路线圖中,它的前身是X100,正如我們當時所說,我們認爲X是一個變量,而不是任何東西的簡稱。
事實證明確實如此,Rubin GPU將使用HBM4內存,並將有8個堆棧,每個堆棧可能有十幾個DRAM高,而2027年的Rubin Ultra GPU將有十幾個HBM4內存堆棧,也可能有更高的堆棧(雖然路线圖沒有這么說)。
我們直到2026年才會看到Nvidia推出新的Arm服務器CPU“Vera”,它是當前“Grace”CPU的繼任者。與之配套的是NVSwitch 6芯片,具有3.6 TB/s的端口,以及帶有1.6 Tb/s端口的ConnectX-9網絡接口卡。
有趣的是,還有一款名爲X1600 IB/Ethernet Switch的產品,這可能意味着Nvidia正在融合其InfiniBand和以太網ASIC,就像十年前Mellanox所做的那樣。或者,這可能意味着Nvidia只是爲了好玩而試圖讓我們產生懷疑。
2027年的路线圖中還透露了一些其他信息,這可能意味着對網卡和交換機的全面超以太網聯盟支持,甚至可能是用於將節點內和跨機架的GPU連接在一起的UALink交換機。
原文來源於:
https://www.nextplatform.com/2024/06/02/nvidia-unfolds-gpu-interconnect-roadmaps-out-to-2027/
中文內容由元宇宙之心(MetaverseHub)團隊編譯,如需轉載請聯系我們。
 打开金色財經App 閱讀全文
打开金色財經,閱讀體驗更佳
金色財經 > 元宇宙之心 > 英偉達官宣下一代最強AI芯片 GPU性能8年提高1053倍
免責聲明: 金色財經作爲开放的資訊分享平台,所提供的所有資訊僅代表作者個人觀點,與金色財經平台立場無關,且不構成任何投資理財建議。
打开金色財經App 閱讀全文
打开金色財經,閱讀體驗更佳
金色財經 > 元宇宙之心 > 英偉達官宣下一代最強AI芯片 GPU性能8年提高1053倍
免責聲明: 金色財經作爲开放的資訊分享平台,所提供的所有資訊僅代表作者個人觀點,與金色財經平台立場無關,且不構成任何投資理財建議。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。