原文標題:Crypto's AI Mirage
原文作者:David Han,Coinbase 機構研究分析師
原文編譯:DAOSquare

去中心化的加密人工智能 (Crypto-AI) 應用在中短期內面臨諸多阻力,可能會妨礙它們的採用。然而,圍繞 Crypto 和人工智能的建設性敘事可能會維持一段時間的交易敘事。
關鍵要點
· 人工智能(AI)和 Crypto 之間的交集範圍很廣,而往往少有人對此有較深的認識。我們認爲,處於交叉點的不同子領域具有截然不同的機會和發展周期。
· 我們通常認爲,對於人工智能產品來說,去中心化本身的競爭優勢是不夠的,它還必須在某些其他關鍵領域與中心化對手保持功能對等。
· 我們的反向觀點是,由於市場對人工智能行業的廣泛關注,導致許多人工智能代幣的價值潛力可能被誇大了,而且許多人工智能代幣在中短期內可能缺乏可持續的需求驅動力。
近年來,隨着人工智能的持續突破 ( 特別是在生成式人工智能方面 ) 造就了人們對人工智能行業的高度關注,並爲介於兩者之間的加密項目提供了機會。我們之前在 2023 年 6 月的一份報告中介紹了該行業的一些可能性,並指出,從 Crypto 的總體資本分配來看,似乎人工智能領域被低估了。此後,加密人工智能領域开始了迅猛的發展。此刻,我們認爲強調可能阻礙其廣泛採用的某些實際挑战非常重要。
人工智能的快速變化使我們對一些 Crypto 平台大膽聲稱其獨特的定位將顛覆整個行業的說法持謹慎態度,這使得大多數人工智能代幣的長期和可持續的價值累積變得不確定,尤其是對於那些固定代幣模型的項目而言更是如此。相反,我們認爲,鑑於更廣泛的市場競爭和監管因素,人工智能領域的一些新興趨勢實際上可能會使基於 Crypto 的創新更難被採用。
也就是說,我們認爲人工智能和 Crypto 之間的交集是廣泛的,並且有着不同的機會。某些子領域的採用速度可能會更快,盡管許多此類領域缺乏可交易的代幣。不過,這似乎並沒有阻礙投資者的胃口。我們發現,人工智能相關的加密代幣的表現受到了人工智能市場熱潮的驅動,即使在比特幣交易走低的日子裏,也可以支持其積極的價格走勢。因此,我們認爲許多與人工智能相關的代幣可能會繼續作爲對人工智能進步的代表被交易。
人工智能的主要趨勢
在我們看來,人工智能領域(與加密人工智能產品相關)最重要的趨勢之一是延續圍繞开源模型的文化。已經有超過 53 萬個模型在 Hugging Face(AI 社區的協作平台)上公开可用,供研究人員和用戶運行和微調。Hugging Face 在 AI 協作中的作用與依賴 Github 進行代碼托管或依賴 Discord 進行社區管理(兩者都在加密中廣泛使用)沒有什么不同。我們認爲這種情況在不久的將來不太可能改變,除非存在嚴重的管理不善。
Hugging Face 上可用的模型範圍從大型語言模型(LLMs)到生成圖像和視頻模型,它們來自 OpenAI、Meta 和 Google 等主要行業參與者,以及獨立开發者。一些开源語言模型甚至在吞吐量方面比最先進的閉源模型具有更好的性能優勢(同時保持可比的輸出質量),這確保了开源模型和商業模式之間一定程度的競爭(見圖 1)。重要的是,我們認爲這個充滿活力的开源生態系統,結合有競爭力的商業部門,已經推動了一個行業,在這個行業中,表現不佳的模型將被競爭所淘汰。
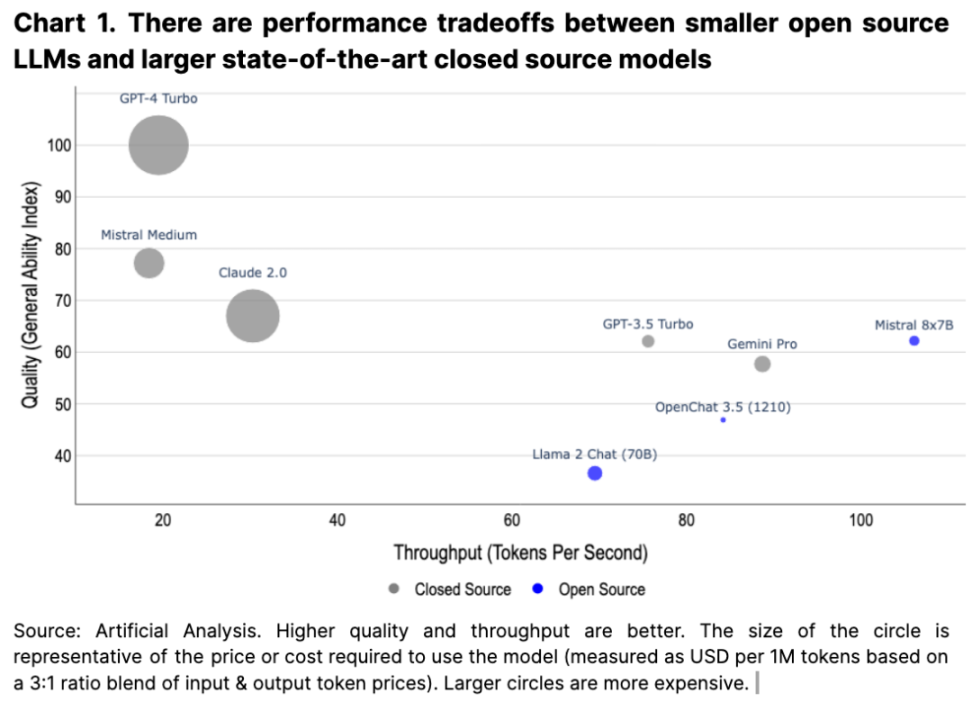
第二個趨勢是小型模型的質量和成本效益不斷提高(早在 2020 年的 LLM 研究中就曾強調這一點,最近在 MIcrosoft 的一篇論文中也強調了這一點),這也與开源文化相吻合,以進一步實現高性能、本地運行的 AI 模型的未來。在某些基准測試下,一些經過微調的开源模型甚至可以勝過領先的閉源模型。在這樣的世界裏,一些人工智能模型可以在本地運行,從而最大限度地去中心化。當然,現有的技術公司將繼續在雲上訓練和運行更大的模型,但在兩者之間的設計空間中會有權衡。
另外,鑑於人工智能模型基准測試的任務日益復雜化(包括數據污染和變化的測試範圍),我們認爲生成模型輸出最終可能最好由終端用戶在自由市場中進行評估。事實上,已有一些工具供終端用戶進行模型輸出的並行比較,也有一些基准測試公司提供相似的服務。對於生成人工智能基准測試的難度,可以從不斷增長的各種开放的 LLM 基准測試中看到,包括 MMLU、HellaSwag、TriviaQA、BoolQ 等,每一種都測試了不同的用例,如常識推理、學術話題和各種問題格式等。
我們在人工智能領域觀察到的第三個趨勢是,具有強大用戶鎖定或具體業務問題的現有平台能夠從人工智能集成中超額受益。例如,Github Copilot 與代碼編輯器的集成增強了已經很強大的开發者環境。將人工智能界面嵌入到如郵件客戶端、電子表格、客戶關系管理軟件等其他工具中也是人工智能的自然用例(例如,Klarna 的 AI 助手可以完成 700 名全職代理的工作)。
然而需要注意的是,在許多這樣的場景中,人工智能模型不會催生新的平台,而只是增強現有的平台。其他改善傳統業務流程的人工智能模型(例如,Meta 的 Lattice 在 Apple 推出 App Tracking Transparency 後恢復了其廣告性能)通常也依賴於專有數據和封閉系統。由於這些類型的人工智能模型是垂直集成到其核心產品中的,並且使用專有數據,因此它們可能會始終保持閉源狀態。
在人工智能硬件和計算領域,我們看到了另外兩個相關的趨勢。首先是計算使用從訓練到推理的過渡。也就是說,當人工智能模型首次开發時,大量計算資源用於通過向模型提供大型數據集來「訓練」模型。現在,它已轉向了模型部署和模型查詢。
英偉達在 2024 年 2 月的財報電話會議中披露,他們大約 40% 的業務是推理,而薩塔亞·納德拉(Sataya Nadella)在微軟的 1 月財報電話會議上也發表了類似的言論,指出他們的 Azure AI 使用「大部分」是用於推理的。隨着這一趨勢的持續,我們認爲尋求將其模型貨幣化的實體將優先考慮能夠以安全和生產就緒 (production-ready) 的方式可靠運行模型的平台。
我們看到的第二個主要趨勢是圍繞硬件架構的競爭格局。英偉達 (Nvidia) 的 H200 處理器將於 2024 年第二季度上市,下一代 B100 的性能預計將進一步翻倍。此外,Google 對其自有的張量處理單元 (TPUs) 的持續支持以及 Groq 的新語言處理單元 (LPUs) 可能在未來幾年中也會增強他們在此領域的市場份額(參見圖 2)。這些發展可能會改變人工智能行業的成本動態,並可能使那些能夠快速調整、大規模採購硬件並設置任何相關物理網絡和开發工具的雲服務提供商受益。
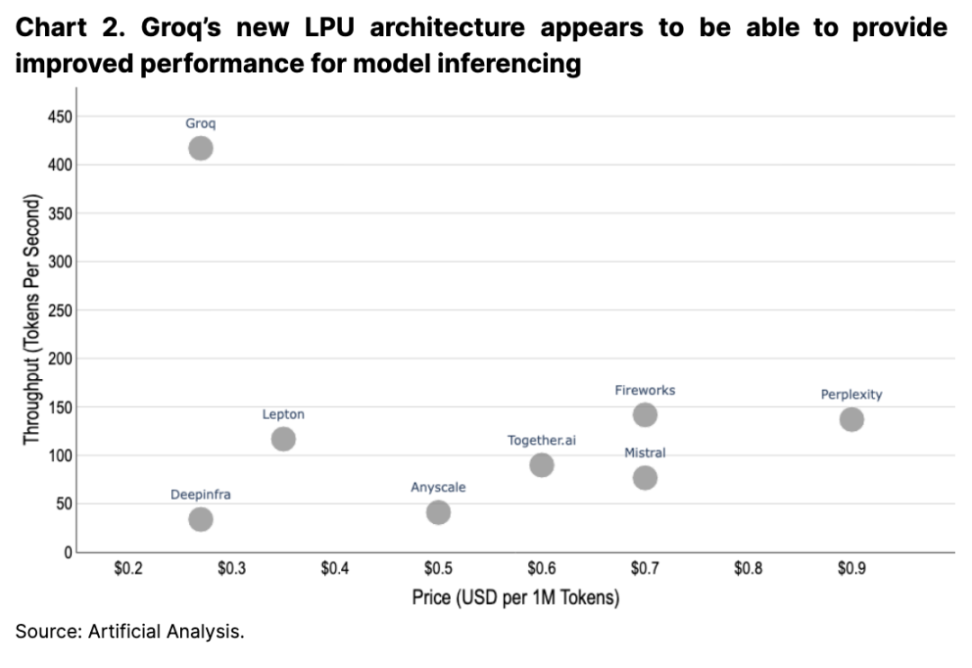
總體而言,人工智能領域是一個新興且發展迅猛的領域。ChatGPT 於 2022 年 11 月首次投放市場迄今不到 1 年半的時間(盡管其底層 GPT-3 模型自 2020 年 6 月以來就已經存在),此後該領域的快速發展令人震驚。盡管有一些關於生成式 AI 模型背後的偏見存在,但我們已經开始看到市場在優勝劣汰上的效應 ( 忽略性能較差的模型,轉而選擇更好的替代品 )。該行業的快速發展和即將出台的法規意味着隨着新的解決方案將不斷湧入市場,該行業的問題空間也會隨之變化。
經常被吹捧的一攬子措施「權力下放解決了 [插入問題]」雖然似乎已經成爲共識,然而在我們看來,對於這樣一個快速創新的領域來說,還爲時過早。而且它還先發制人地解決了可能並不一定存在的中心化問題。現實情況是,通過許多不同公司和开源項目之間的競爭,人工智能行業在技術和業務垂直領域已經有很多去中心化的現象。此外,在技術和社會層面上,真正去中心化的協議在決策和共識過程上比中心化協議要慢很多。這可能會對在人工智能發展所處的現時階段中尋求平衡去中心化和具有競爭力的產品構成障礙。也就是說,我們確實認爲 Crypto 和人工智能之間存在一些有意義的協同作用,但它更多的是在更長的時間範圍內。
確定機會範圍
從廣義上講,我們將人工智能和 Crypto 的交叉點分爲兩大類。首先是人工智能產品改善加密行業的用例。這包括創建人類可讀的交易、改進區塊鏈數據分析,以及在無需許可的協議中使用模型輸出的場景。第二類則是旨在通過 Crypto 的計算、驗證、身份等去中心化方法打破傳統 AI 流程的用例。
在我們看來,在前一類別中,與業務一致的那些場景中的用例是明確的,我們相信,盡管仍然存在重大的技術挑战,但從長期來看,它們在更復雜的鏈上推理模型場景中依然會有前景。中心化的 AI 模型可以像任何其他以技術爲中心的行業一樣改進 Crypto,例如开發者工具、代碼審計,以及將人類語言轉化爲鏈上動作。但目前這一領域的投資通常通過風險投資獲而歸私人公司所有,因此通常被公开市場所忽視。
然而,對我們來說不太確定的是第二類的價值主張(即 Crypto 將打破現有的人工智能格局)。後一類的挑战取代了技術性的挑战(我們認爲從長遠來看,技術性挑战通常是可以解決的),並且是與更廣泛的市場和監管力量的艱難較量。然而盡管如此,一個現實現象是,最近對人工智能 + Crypto 的大部分關注都集中在這一類別上,因爲這些用例更適合創造流動代幣。這是我們在下一節中的重點,在 Crypto 中,與中心化的 AI 工具相關的流動性代幣相對較少(暫時如此)。
Crypto 在 AI 中的作用
爲了簡化,我們通過 AI 流程的四個主要階段來分析 Crypto 對 AI 的潛在影響,這四個階段分別是:(1)數據的收集、存儲和處理,(2)模型的訓練和推理,(3)模型輸出的驗證,(4)AI 模型輸出跟蹤。這些領域已經出現了一大批新的加密人工智能項目,盡管我們認爲在中短期內,許多項目將面臨需求方生成的重大挑战,以及來自中心化公司和开源解決方案的激烈競爭。
專有數據
數據是所有 AI 模型的基礎,也許是專業 AI 模型性能的關鍵差異化因素。歷史區塊鏈數據本身就是模型的一種新的豐富數據源,某些項目(如 Grass)也旨在利用 Crypto 激勵措施從开放的互聯網中獲取新的數據集。在這方面,Crypto 有機會提供行業特定的數據集,並激勵創建新的有價值的數據集。(Reddit 最近與 Google 達成的 6000 萬美元年度數據許可協議預示着未來數據集貨幣化的增長趨勢)
許多早期的模型(如 GPT-3)混合使用了 CommonCrawl、WebText2、書籍和維基百科等开放數據集,並在 Hugging Face 上免費提供了類似的數據集(目前托管超過 110,000 個選項)。然而,可能是爲了保護其商業利益,許多最近發布的閉源模型並沒有公开他們的最終訓練數據集組合。我們認爲,專有數據集的趨勢,特別是在商業模式中,仍將繼續下去,並導致數據許可的重要性增加。
現有的中心化數據市場已經在幫助彌合數據提供者和消費者之間的差距,我們認爲這將爲开源數據目錄和企業競爭者之間創造一個新興的去中心化數據市場解決方案的機會空間。在沒有法律結構支持的情況下,一個純粹的去中心化數據市場還需要構建標准化的數據接口和通道,驗證數據完整性和配置,並解決其產品的冷啓動問題。同時還需要平衡市場參與者之間的代幣激勵。
另外,去中心化存儲解決方案最終也可能在人工智能行業找到一個利基市場,盡管我們認爲在這方面仍然存在不小的挑战。一方面,用於分發开源數據集的渠道已經存在並已被廣泛使用。另一方面,許多專有數據集的所有者有嚴格的安全性和合規性要求。目前還沒有任何監管途徑可以作用於在 Filecoin 和 Arweave 等去中心化存儲平台上托管敏感數據。事實上,許多企業仍在從本地服務器過渡到中心化雲存儲提供商。在技術層面上,這些網絡的去中心化性質目前也與敏感數據存儲的某些區域性問題和物理數據孤島要求不兼容。
雖然在去中心化存儲解決方案和成熟的雲提供商之間也進行價格比較表明,就單個儲存單元而言,去中心化方案可能更便宜,但我們認爲這忽略了更大的問題。首先,除了日常運營費用之外,還需要考慮到在供應商之間遷移系統所需的前期成本。其次,基於 Crypto 的去中心化存儲平台需要去匹配過去二十年發展起來的成熟雲系統所提供的更好的工具和集成。從業務運營的角度來看,雲解決方案的成本更可預測,並且提供了合同義務和專門的支持團隊,而且還擁有龐大的开發者人才庫。
同樣值得注意的是,僅與「三大」雲提供商(AWS,Google 雲平台和 Microsoft Azure)的粗略比較是不完整的。還有數十家低成本的雲公司也通過提供更便宜的、基本的服務器等服務來爭奪市場份額。在我們看來,近期而言,他們才是那些成本敏感型消費者的真正的主要競爭對手。也就是說,最近的創新,如 Filecoin 的數據計算和 Arweave 的 ao 計算環境,可能會爲即將到來的一些創新項目發揮作用,這些項目通常使用的是不太敏感的數據集,或者是對成本最爲敏感(可能更小)的公司,而這些公司尚未鎖定供應商。
因此,雖然在數據領域肯定有新的 Crypto 產品的空間,但我們認爲,短期突破將發生在它們可以產生獨特的價值主張的情況下。在我們看來,去中心化產品與傳統和开源競爭對手正面競爭的領域將需要更長的時間才能取得實質性進展。
訓練和推理模型
Crypto 中的去中心化計算(DeComp)領域也旨在成爲中心化雲計算的替代品,部分原因是現有的 GPU 供應緊縮。一種針對這種短缺的提出的解決方案,例如 Akash 和 Render 等協議所採用的是將闲置的計算資源重新整合進一個中心化網絡中,從而降低中心化雲提供商的成本。據初步指標顯示,此類項目似乎在用戶和供應商的採用率上均獲得了增長。例如,Akash 從今年年初至今的活躍租賃(即用戶數量)增加了三倍(見圖 3),這主要是由於其存儲和計算資源的使用量增加。
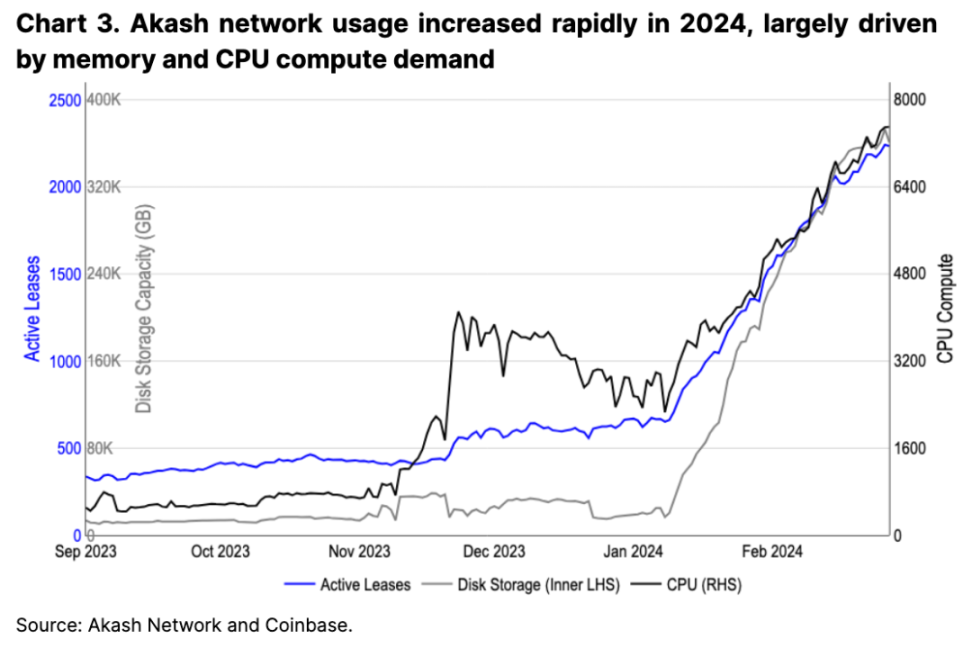
然而,自 2023 年 12 月達到峰值以來,支付給網絡的費用實際上已經下降,因爲可用 GPU 的供應超過了對這些資源的需求增長。也就是說,隨着越來越多的提供商加入該網絡,租賃的 GPU 數量(按比例來看似乎是最大的收入驅動因素)已經下降(見圖 4)。對於計算定價可以根據供需變化而變化的網絡,如果供應端增長超過需求端,我們不清楚持續的、由使用驅動的原生代幣需求最終將從何而來。我們認爲,未來可能需要重新審視這種代幣模型,以優化市場變化,盡管這種變化的長期影響目前尚不明確。
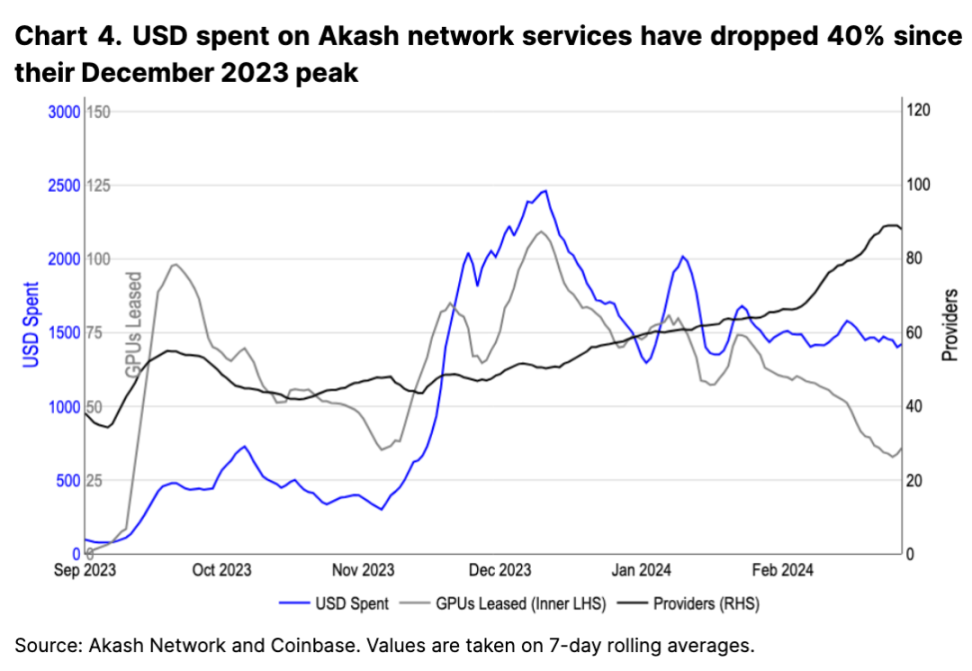
在技術層面,去中心化計算解決方案也面臨着網絡帶寬限制的挑战。對於需要多節點訓練的大型模型,物理網絡基礎設施層起着至關重要的作用。數據傳輸速度、同步开銷,以及對某些分布式訓練算法的支持意味着需要特定的網絡配置和自定義網絡通信(如 InfiniBand)來促進其高效執行。這導致一旦集群規模超過一定範圍,便很難以去中心化的方式實現。
總體而言,我們認爲去中心化計算(和存儲)的長期成功面臨着來中心化雲提供商的激烈競爭。在我們看來,任何採用都將是一個長期過程,至少可以參考雲服務採用周期。鑑於去中心化網絡开發的技術復雜性增加,加上缺乏類似可擴展的开發和銷售團隊,我們認爲完全執行去中心化計算愿景將是一個艱難的旅程。
驗證和信任模型
隨着人工智能模型在我們的生活中變得越來越重要,人們越來越擔心它們的輸出質量和偏見。某些加密項目旨在通過利用一套算法來評估不同類別的輸出,從而找到一種去中心化的、基於市場的解決方案來解決這個問題。然而,上述圍繞模型基准測試的挑战,以及明顯的成本、吞吐量和質量權衡,使得正面競爭具有一定的挑战性。BitTensor 是該類別中最大的聚焦於人工智能的加密貨幣之一,旨在解決這個問題,盡管它依然存在一些可能阻礙其廣泛應用的技術挑战(見附錄 1)。
另外,無需信任的模型推理(即證明模型輸出實際上是由所聲稱的模型生成的)是 Crypto x AI 的另一個積極研究領域。然而我們認爲,隨着开源模型規模的縮小,這些解決方案可能會在需求方面面臨挑战。在一個可以下載並在本地運行模型,並通過已經建立的文件哈希 / 校驗和方法驗證內容完整性的世界裏,無需信任的推理的角色重要性就不那么明確了。誠然,許多人 LLM 還不能通過手機等輕量級設備進行訓練和運行,但強大的台式電腦(如用於高端遊戲的台式電腦)已經可以用來運行許多高性能模型。
數據來源和身份
隨着生成式人工智能的輸出與人類的輸出越來越難以區分,跟蹤人工智能生成內容的重要性也成爲人們關注的焦點。GPT-4 通過圖靈測試的速度是 GPT-3.5 的 3 倍,我們幾乎可以肯定,在不遠的某一天,我們將無法區分在线人格是來自機器還是真實的人類。在這樣的世界裏,確定在线用戶的人性以及給 AI 生成的內容填加水印將成爲關鍵功能。
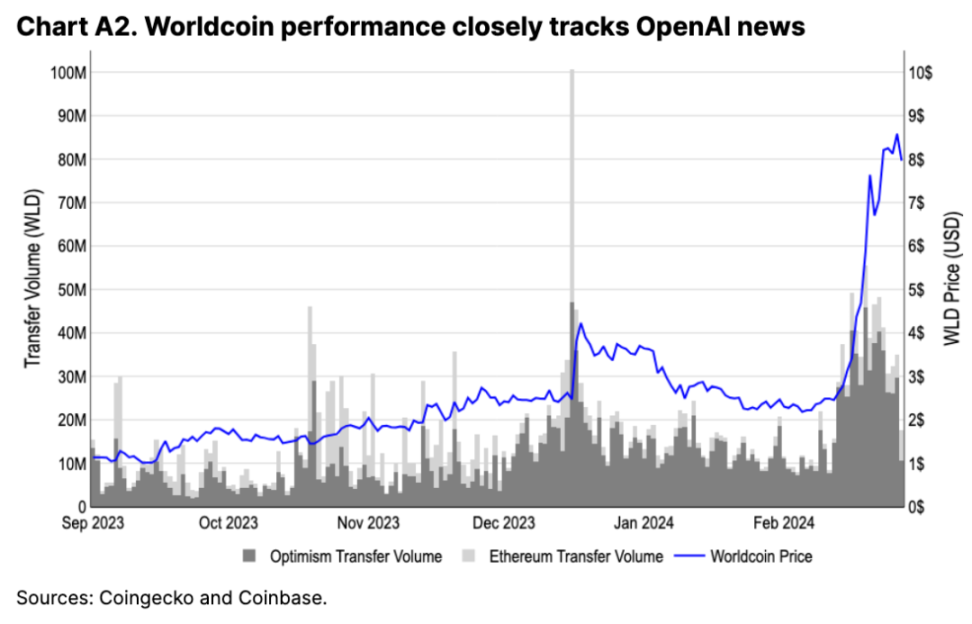
像 Worldcoin 這樣的去中心化標識符和人格證明機制旨在解決前一個問題,即在鏈上識別人類。同樣,將數據哈希發布到區塊鏈可以通過驗證內容的年齡和來源,從而助力數據來源。然而,與前面的部分類似,我們認爲基於 Crypto 的解決方案的可行性必須與中心化的替代方案進行權衡。
一些國家,比如中國,將在线人格與政府控制的數據庫聯系起來。盡管世界上大部分地區都沒有那么集中化,但 KYC 提供商聯盟也可以提供獨立於區塊鏈技術的人格證明解決方案(可能以類似於構成當今互聯網安全基石的可信證書頒發機構的方式)。還有關於 AI 水印的研究正在進行中,以在文本和圖像輸出中嵌入隱藏信號,以允許算法檢測內容是否由 AI 生成。包括 Microsoft,Anthropic 和 Amazon 在內的許多領先的 AI 公司都已經公开承諾在其生成的內容中添加此類水印。
此外,出於合規性原因,許多現有的內容提供商已經受到信任,可以保留內容元數據的嚴格記錄。因此,用戶通常信任與社交媒體發布相關的元數據(盡管不是其屏幕截圖),即使它們是中心化存儲的。這裏需要注意的是,任何基於 Crypto 的數據來源和身份解決方案都需要與用戶平台集成才能廣泛有效。因此,雖然基於 Crypto 的解決方案在證明身份和數據來源等方面從技術說是可行的,但我們也認爲它們的採用並非既定事實,最終將取決於業務,合規和監管要求。
交易 AI 敘事
盡管有上述問題,但從 23 年第 4 季度开始,許多 AI 代幣的表現都優於比特幣和以太幣,以及 Nvidia 和 Microsoft 等主要 AI 股票。我們認爲這是因爲 AI 代幣通常受益於更廣泛的 Crypto 市場以及相關人工智能熱潮的相關表現(見附錄 2)。因此,即使比特幣價格下跌,以人工智能爲重點的代幣也會經歷價格上漲波動,從而在比特幣下行期間產生上行的波動性。圖 5 展示了比特幣交易下跌的日子裏 AI 代幣的表現。

總體而言,我們仍然認爲人工智能敘事交易中缺少許多短期可持續的需求驅動因素。由於缺乏明確的採用預測和指標,導致了各種 meme 式的投機情緒佔據了廣泛空間,而在我們看來,這些推測可能不是長期可持續的。最終,價格和效用將會趨同,而懸而未決的問題是需要多長時間,以及效用是否會上升以匹配價格,反之亦然。也就是說,我們確實認爲一個可持續的建設性 Crypto 市場和優於人工智能行業的表現可能會在一段時間內維持強大的 Crypto AI 敘事。
結論
Crypto 在人工智能中的作用並非存在於真空中,任何去中心化平台都在與現有的中心化替代方案競爭,並必須在更廣泛的業務和監管要求的背景下進行分析。因此我們認爲,僅僅爲了「去中心化」而取代中心化提供商不足以推動有意義的市場採用。生成式人工智能模型已經存在了幾年,並且由於市場競爭和开源軟件,已經保持了一定程度的去中心化。
本報告中反復出現的一個主題是,基於加密的解決方案雖然在技術上通常是可行的,但仍需要大量的工作才能達到與更中心化的平台的功能對等,並且前提是這些平台不會在此期間停滯不前。事實上,由於共識機制,中心化开發通常比去中心化更快,這可能會給人工智能這樣快速發展的領域帶來挑战。
有鑑於此,我們認爲 AI 與 Crypto 的重疊仍處於起步階段,隨着更廣泛的人工智能領域的發展,未來幾年可能會迅速變化。目前許多 Crypto 行內人士所設想的去中心化的 AI 未來是無法保證其實現的,事實上,人工智能行業本身的未來在很大程度上仍未確定。因此,我們認爲謹慎的做法是仔細駕馭這樣的市場,並更深入地研究基於加密貨幣的解決方案如何真正提供有意義的更好的替代方案,或者至少了解潛在的交易敘述。因此,我們認爲在這樣的市場中謹慎行事並更深入地研究基於 Crypto 的解決方案如何真正提供一個有意義的更優選擇,或者至少,理解底層的交易敘事是明智的。
附錄 1:BitTensor
BitTensor 在其 32 個子網中激勵不同的情報市場。這旨在通過使子網所有者能夠創建類似遊戲般的約束來從信息提供者那裏提取情報,從而解決基准測試的一些問題。例如,其旗艦子網 1 以文本提示爲中心,並激勵那些「根據該子網中的子網驗證者發送的提示產生最佳響應」的礦工。也就是說,它獎勵那些能夠對給定提示生成最佳文本響應的礦工,這是由該子網中的其他驗證者判斷的。這使得網絡參與者試圖在各個市場創建模型的智能經濟成爲可能。
然而,這種驗證和獎勵機制仍處於早期階段,容易受到對抗性攻擊,特別是如果模型使用了其他包含偏見的模型進行評估(盡管在這方面已經取得了進展,使用新的合成數據用於評估某些子網)。對於語言和藝術等「模糊」輸出尤其如此,在這些輸出中,評估指標可能是主觀的,因此也會導致模型性能的多重基准的出現。
例如,BitTensor 的子網 1 的驗證機制在實踐中需要:
驗證者生成一個或多個參考答案,所有礦工的響應都會被比較。那些與參考答案最相似的人將獲得最高的獎勵,並最終獲得最大的激勵。
當前的相似性算法使用字符串文字和語義匹配的組合作爲獎勵的基礎,但很難通過一組有限的參考答案來捕捉不同的風格偏好。
目前尚不清楚由 BitTensor 激勵結構產生的模型最終是否能夠勝過中心化模型(或者表現最好的模型是否會轉向 BitTensor),或者它如何能夠適應其他權衡因素,如模型規模和基礎計算成本。一個用戶可以自由選擇適合他們偏好的模型的市場,也許能夠通過「看不見的手」實現類似的資源分配。也就是說,BitTensor 確實試圖在不斷擴大的問題空間中解決一個極具挑战性的問題。
附錄 2:WorldCoin
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。