作者:新智元
來自東京大學的Suspicion Agent利用GPT-4,在不完全信息博弈中表現出了高階的心智理論能力(ToM)。
在完全信息博弈中,每個博弈者都知道所有信息要素。
但不完全信息博弈不同,它模擬了現實世界中在不確定或不完全信息下進行決策的復雜性。
GPT-4作爲目前最強大模型,具有非凡的知識檢索和推理能力。
但GPT-4能否利用已學習到的知識進行不完全信息博弈?
爲此,東京大學的研究人員引入了Suspicion Agent這一創新智能體,通過利用GPT-4的能力來執行不完全信息博弈。

論文地址:https://arxiv.org/abs/2309.17277
在研究中,基於GPT-4的Suspicion Agent能夠通過適當的提示工程來實現不同的功能,並在一系列不完全信息牌局中表現出了卓越的適應性。
最重要的是,博弈過程中,GPT-4表現出了強大的高階心智理論(ToM)能力。
GPT-4可以利用自己對人類認知的理解來預測對手的思維過程、易感性和行動。
這意味着GPT-4具備像人類一樣理解他人並有意影響他人的行爲。
同樣的,基於GPT-4的智能體在不完全信息博弈中的表現也優於傳統算法,這可能會激發LLM在不完全信息博弈中的更多應用。
01 訓練方法
爲了讓LLM能夠在沒有專門訓練的情況下玩各種不完全信息博弈遊戲,研究人員將整個任務分解爲下圖所示的幾個模塊,如觀察解釋器、遊戲模式分析和規劃模塊。
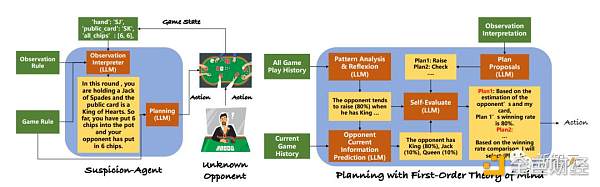
並且,爲了緩解LLM在不完全信息遊戲中可能會被誤導這一問題,研究人員首先开發了結構化提示,幫助LLM理解遊戲規則和當前狀態。
對於每種類型的不完全信息博弈,都可以編寫如下結構化規則描述:
一般規則:遊戲簡介、回合數和投注規則;
動作描述:(動作 1 的描述)、(動作 2 的描述)......;
單局輸贏規則:單局輸贏或平局的條件;
輸贏回報規則:單局輸贏的獎勵或懲罰;
整局輸贏規則:對局數和整體輸贏條件。
在大多數不完全信息博弈環境中,博弈狀態通常表示爲低級數值,如單擊向量,以方便機器學習。
但通過LLM,就可以將低層次的博弈狀態轉換爲自然語言文本,從而幫助模式的理解:
輸入說明:接收到的輸入類型,如字典、列表或其他格式,並描述遊戲狀態中的元素數量以及每個元素的名稱;
元素描述:(元素 11 的描述,(元素 2 的描述),....
轉換提示:將低級遊戲狀態轉換爲文本的更多指南。

在不完全信息博弈中,這種表述方式能更容易理解與模型之間的交互。
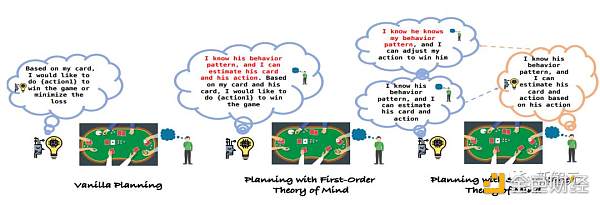
研究人員引入了一種虛無規劃方法,該方法具有一個Reflexion模塊,旨在自動檢查對局歷史,使LLMs能夠從歷史經驗中學習和改進規劃,以及一個單獨的規劃模塊,專門用於做出相應的決策。
然而,虛無的規劃方法往往難以應對不完全信息博弈中固有的不確定性,尤其是在面對善於利用他人策略的對手時。
受這種適應性的啓發,研究人員設計出了一種新的規劃方法,即利用LLM的ToM能力來了解對手的行爲,從而相應地調整策略。
02 實驗定量評估
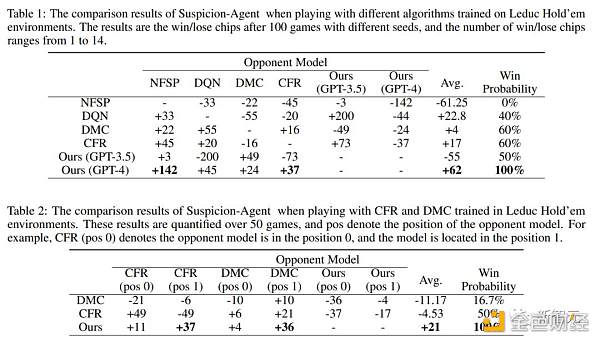
如表1所示,Suspicion Agent優於所有基线,並且基於GPT-4的Suspicion Agent在比較中獲得了最高的平均籌碼數。
這些發現有力地展示了在不完全信息博弈領域採用大型語言模型的優勢,同時也證明了研究提出框架的有效性。
下圖表明了Suspicion Agent和基线模型的行動百分比。
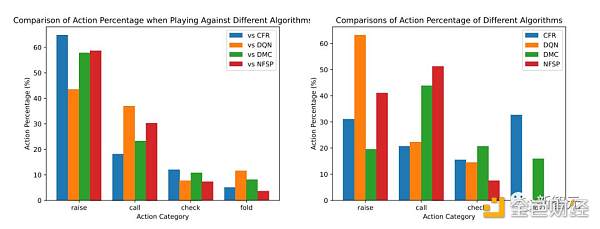
可以觀察到:
Suspicion Agent vs CFR:CFR算法是一種保守策略,它傾向於保守,經常在持有弱牌時棄牌。
而Suspicion Agent成功識別了這一模式,並策略性地選擇更頻繁地加注,向 CFR 施加棄牌壓力。
這使得即使Suspicion Agent的牌很弱或與CFR的牌相當的情況下,它積累了更多籌碼。
Suspicion Agent vs DMC:DMC基於搜索算法,採用了更多樣化的策略,包括虛張聲勢。它經常在自己手牌最弱和最強時都會加注。
作爲回應,Suspicion Agent根據自己的手牌和觀察到的DMC的行爲,減少了加注頻率,並更多地選擇跟注或棄牌。
Suspicion Agent vs DON:DON算法的立場更加激進,幾乎總是用強牌或中級牌加注,從不棄牌。
Suspicion Agent發現了這一點,並反過來盡量減少自己的加注,更多地根據公共牌和DON的行動選擇跟注或棄牌。
Suspicion Agent Vs NFSP:NFSP表現出跟注策略,選擇總是跟注並從不棄牌。
Suspicion Agent的應對方式是減少加注頻率,並根據公共牌和NFSP觀察到的行動選擇棄牌。
根據上述分析結果,可以看到Suspicion Agent具有很強的適應性,能夠利用其他各種算法所採用策略的弱點。
這充分說明了大語言模型在不完美信息博弈中的推理和適應能力。
03 定性評估
在定性評估中,研究人員在三個不完全信息博弈遊戲(Coup、Texas Hold'emLimit 和 Leduc Hold'em)中對Suspicion Agent進行了評估。
Coup,中文翻譯是政變,這是一種紙牌遊戲,玩家扮演政治家,試圖推翻其他玩家的政權。遊戲的目標是在遊戲中存活並積累權力。
Texas Hold'em Limit,即德州撲克(有限注),是一種非常流行的撲克牌遊戲,有多個變體。「Limit」表示在每輪下注中有固定的上限,這意味着玩家只能下固定數額的賭注。
Leduc Hold'em是則是德州撲克的一個簡化版本,用於研究博弈論和人工智能。
在每種情況下,Suspicion Agent手中有一張Jack,而對手要么有一張Jack,要么有一張Queen。
對手最初選擇跟注而不是加注,暗示他們手牌較弱。在普通計劃策略下,Suspicion Agent選擇跟注以查看公共牌。
當這揭示出對手手牌較弱時,對手迅速加注,使Suspicion Agent處於不穩定的局面,因爲Jack是最弱的手牌。

在一階理論心智策略下,Suspicion Agent選擇棄牌,以最小化損失。這個決定是基於觀察到對手通常在手中有Queen或Jack時才跟注。

然而,這些策略未能充分利用對手手牌的推測弱點。這一缺點源於它們不考慮Suspicion Agent的舉動可能如何影響對手的反應。

相比之下,如圖9所示,簡單的提示能夠讓Suspicion Agent了解如何影響對手的行動。有意選擇加注會給對手帶來壓力,促使他們棄牌並最小化損失。
因此,即使手牌的強度相似,Suspicion Agent也能夠贏得許多比賽,從而比基线贏得更多的籌碼。

此外,如圖10所示,在對手跟注或回應Suspicion Agent的加注情況下(這表明對手手牌強大),Suspicion Agent就會迅速調整策略,選擇棄牌以防止進一步損失。

這顯示了Suspicion Agent的出色战略靈活性。
04 消融研究與組件分析
爲了探索不同階ToM感知規劃方法如何影響大型語言模型的行爲,研究人員在Leduc Hold'em和plaagainst CFR上進行了實驗和比較。
圖5中展示了採用不同ToM水平規劃的Suspicion Agent的行動百分比,並在表3中展示了籌碼收益結果。
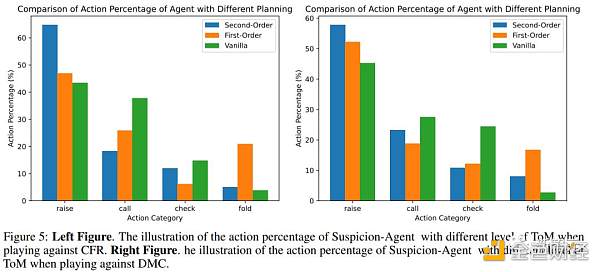
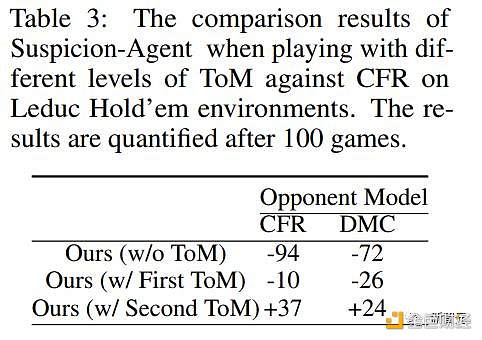
表3:Suspicion Agent在使用不同級別ToM與CFRonLeduc Hold'em環境對弈時的比較結果以及100局遊戲後的量化結果
可以觀察到:
基於Reflexion modulevanilla規劃在對局過程中傾向於更多地跟注和過牌(在對陣CFR和DMC時跟注和過牌比例最高),這無法施加壓力使對手棄牌,並導致許多不必要的損失。
但如表3所示,vanilla計劃的籌碼收益最低。
利用一階ToM,Suspicion Agent能夠根據自己的牌力和對對手牌力的估計做出決策。
因此,它加注的次數會多於普通計劃,但它棄牌的次數往往多於其他策略,目的是盡量減少不必要的損失。然而,這種謹慎的方法會被精明的對手模型所利用。
例如,DMC經常在拿着最弱的一手牌時加注,而CFR有時甚至會在拿着中級牌時加注,以對Suspicion Agent施加壓力。在這些情況下,Suspicion Agent的加倍傾向會導致損失。
相比之下,Suspicion Agent更擅長識別和利用對手模型的行爲模式。
具體來說,當CFR選擇過牌(通常表示手牌較弱)或當DMC過牌(表明其手牌與公共牌不一致)時,Suspicion Agent會以虛張聲勢的方式加注,誘使對手棄牌。
因此,Suspicion Agent在三種規劃方法中表現出最高的加注率。
這種激進的策略讓Suspicion Agent即使手持弱牌也能積累更多籌碼,從而最大限度地提高籌碼收益。
爲了評估後視觀察的影響,研究人員進行了一項後視觀察不納入當前遊戲的消融研究。
如表4和表5所示,在沒有後視觀察觀察的情況下,Suspicion Agent仍能保持其相對於基线方法的性能優勢。
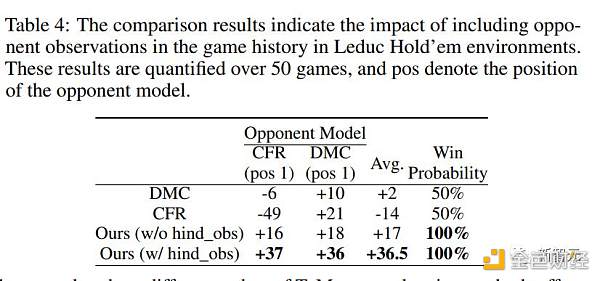
表4:比較結果表明了在萊德克牌局環境中將對手觀察結果納入對局歷史的影響

表5:比較結果表明,當Suspicion Agent在 Leduc Hold'em 環境中與CFR對弈時,在對局歷史中加入對手觀察結果的影響。結果是使用不同種子進行100局對局後的輸贏籌碼,輸贏籌碼數從1到14不等
05 結論
Suspicion Agent沒有進行任何專門的訓練,僅僅利用GPT-4的先驗知識和推理能力,就能在Leduc Hold'em等不同的不完全信息遊戲中战勝專門針對這些遊戲訓練的算法,如CFR和NFSP。
這表明大模型具有在不完全信息遊戲中取得強大表現的潛力。
通過整合一階和二階理論心智模型,Suspicion Agent可以預測對手的行爲,並相應調整自己的策略。這使得它可以對不同類型對手進行適應。
Suspicion Agent還展示了跨不同不完全信息遊戲的泛化能力,僅僅根據遊戲規則和觀察規則,就可以在Coup和Texas Hold'em等遊戲中進行決策。
但Suspicion Agent也有着一定的局限性。例如,由於計算成本限制,對不同算法的評估樣本量較小。
以及推理成本高昂,每局遊戲耗費接近1美元,並且Suspicion Agent的輸出對提示的敏感性較高,存在hallucination的問題。
同時,在進行復雜推理和計算時,Suspicion Agent的表現也不盡人意。
未來,Suspicion Agent將在計算效率、推理魯棒性等方面進行改進,並支持多模態和多步推理,來實現對復雜遊戲環境的更好適應。
同時,Suspicion Agent在不完全信息博弈遊戲中的應用,也可以遷移到未來多模態信息的整合,模擬更真實的交互、擴展到多玩家遊戲環境中。
參考資料:
https://arxiv.org/abs/2309.17277
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。