 免責聲明: 內容不構成买賣依據,投資有風險,入市需謹慎!
免責聲明: 內容不構成买賣依據,投資有風險,入市需謹慎!
生於邊緣:去中心化算力網絡如何賦能Crypto與AI?

 YoubiCapitai
企業專欄
剛剛
YoubiCapitai
企業專欄
剛剛
 關注
關注
作者:Jane Doe, Chen Li,通訊作者:Youbi投資團隊
1 AI與Crypto的交點
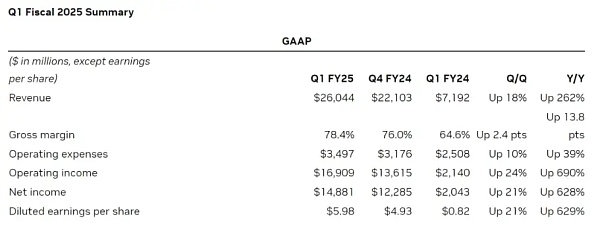
5月23日,芯片巨頭英偉達發布了2025財年第一季度財報。財報顯示,英偉達第一季度營收爲260億美元。其中,數據中心營收較去年增長427%,達到驚人的226億美元。英偉達能夠憑借一己之力拯救美股大盤的財務表現背後,反映的是全球科技公司爲了角逐AI賽道而爆發的算力需求。越是頂尖的科技公司在AI賽道布局的野心越大,相應的,這些公司對於算力的需求也呈指數級增長。根據TrendForce的預測,2024年美國四大主要雲服務提供商:微軟、谷歌、AWS和Meta的對於高端AI服務器的需求預計分別將佔全球需求的20.2%、16.6%、16%和10.8%,總計超60%。
圖片來源: https://investor.nvidia.com/financial-info/financial-reports/default.aspx
“芯片緊缺“連續成爲近幾年的年度熱詞。一方面,大語言模型(LLM)的training和inference需要大量算力支撐;並且隨着模型的迭代,算力成本和需求呈指數級增加。另一方面,像Meta這樣的大公司會採購巨量的芯片,全球的算力資源都向這些科技巨頭傾斜,使得小型企業越來越難以獲得所需的算力資源。小型企業面臨的困境不僅來自於激增的需求導致的芯片供給不足,還來自於供給的結構性矛盾。目前,在供給端仍存在着大量闲置的GPU,比如,一些數據中心存在大量闲置的算力(使用率僅在12% – 18%),加密挖礦中由於利潤的減少也闲置出來大量的算力資源。雖然這些算力並非都適合AI訓練等專業的應用場景,但消費級硬件在其他領域,如AI inference、雲遊戲渲染、雲手機等領域仍然可以發揮巨大作用。整合並利用這部分算力資源的機會是巨大的。
把視线從AI轉到crypto,在加密市場沉寂了三年之後,終於又迎來了又一輪牛市,比特幣價格屢創新高,各種memecoin層出不窮。雖然AI和Crypto作爲buzzword火了這些年,但人工智能和區塊鏈作爲兩項重要技術仿佛兩條平行线,遲遲沒有找到一個“交點”。今年年初,Vitalik發表了一篇名爲“The promise and challenges of crypto + AI applications” 的文章,討論了未來AI和crypto相結合的場景。Vitalik在文中提到了很多的暢想,包括利用區塊鏈和MPC等加密技術對AI進行去中心化的training和inference,可以將machine learning的黑箱打开,從而讓AI model更加trustless等等。這些愿景若要實現還有很長一段路要走。但其中Vitalik提到的其中一個用例——利用crypto的經濟激勵來賦能AI,也是一個重要且在短時間內可以實現的一個方向。去中心化算力網絡便是現階段AI + crypto最合適的場景之一。
2 去中心化算力網絡
目前,已經有不少項目在去中心化算力網絡的賽道上發展。這些項目的底層邏輯是相似的,可以概括爲: 利用token激勵算力持有者參與網絡提供算力服務,這些零散的算力資源可以匯集成有一定規模的去中心化算力網絡。這樣既能提高闲置算力的利用率,又能以更低的成本滿足客戶的算力需求,實現买方賣方雙方的共贏。
爲了使讀者在短時間內獲得對此賽道的整體把握,本文將從微觀—宏觀兩個視角對具體的項目和整個賽道進行解構,旨在爲讀者提供分析視角去理解每個項目的核心競爭優勢以及去中心化算力賽道整體的發展情況。筆者將介紹並分析五個項目: Aethir、io.net、Render Network、Akash Network、Gensyn,並對項目情況和賽道發展進行總結和評價。
從分析框架而言,如果聚焦於一個具體的去中心化算力網絡,我們可以將其拆解成四個核心的構成部分:
硬件網絡:將分散的算力資源整合在一起,通過分布在全球各地的節點來實現算力資源的共享和負載均衡,是去中心化算力網絡的基礎層。
雙邊市場:通過合理的定價機制和發現機制將算力提供者與需求者進行匹配,提供安全的交易平台,確保供需雙方的交易透明、公平和可信。
共識機制:用於確保網絡內節點正確運行並完成工作。共識機制主要用於監測兩個層面:1)監測節點是否在线運行,處於可以隨時接受任務的活躍狀態;2)節點工作證明:該節點接到任務後有效正確地完成了任務,算力沒有被用於其他目的而佔用了進程和线程。
代幣激勵:代幣模型用於激勵更多的參與方提供/使用服務,並且用token捕獲這種網絡效應,實現社區收益共享。
如果鳥瞰整個去中心化算力賽道,Blockworks Research的研報提供了一個很好的分析框架,我們可以將此賽道的項目position分爲三個不同的layer。
Bare metal layer: 構成去中心化計算棧的基礎層,主要的任務是收集原始算力資源並且讓它們能夠被API調用。
Orchestration layer: 構成去中心化計算棧的中間層,主要的任務是協調和抽象,負責算力的調度、擴展、操作、負載均衡和容錯等。主要作用是“抽象”底層硬件管理的復雜性,爲終端用戶提供一個更加高級的用戶界面,服務特定的客群。
Aggregation layer: 構成去中心化計算棧的頂層,主要的任務是整合,負責提供一個統一的界面讓用戶可以在一處實現多種計算任務,比如AI訓練、渲染、zkML等等。相當於多個去中心化計算服務的編排和分發層。
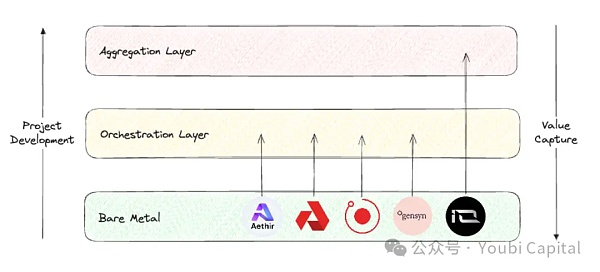
圖片來源:Youbi Capital
根據以上兩個分析框架,我們將對選取的五個項目做一個橫向的對比,並從四個層面——核心業務、市場定位、硬件設施和財務表現對其進行評價。
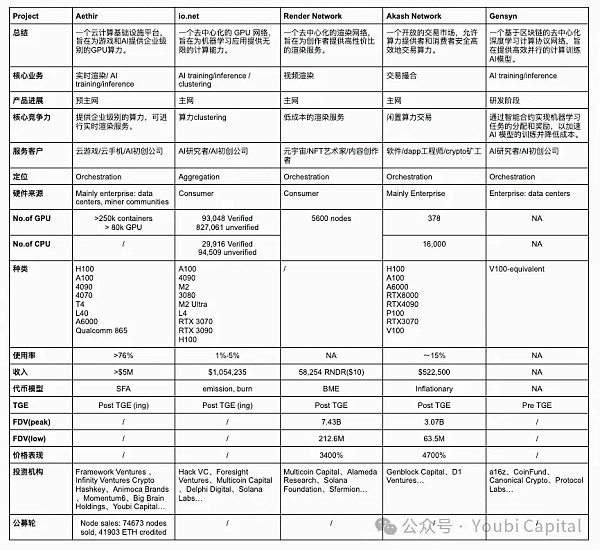
2.1 核心業務
從底層邏輯來講,去中心化算力網絡是高度同質化的,即利用token激勵闲置算力持有者提供算力服務。圍繞這個底層邏輯,我們可以從三個方面的差異來理解項目核心業務的不同:
闲置算力的來源:
市面上闲置算力有兩種主要的來源:1)data centers, 礦商等企業手裏闲置算力;2)散戶手裏的闲置算力。數據中心的算力通常是專業級別的硬件,而散戶通常會購买消費級別的芯片。
Aethir、Akash Network和Gensyn的算力主要是從企業收集的。從企業收集算力的好處在於:1)企業和數據中心通常擁有更高質量的硬件和專業維護團隊,算力資源的性能和可靠性更高;2)企業和數據中心的算力資源往往更同質化,並且集中的管理和監控使得資源的調度和維護更加高效。但相應的,這種方式對於項目方的要求較高,需要項目方有與掌握算力的企業有商業聯系。同時,可擴展性和去中心化程度會受到一定程度的影響。
Render Network和io.net主要是激勵散戶提供手中的闲置算力。從散戶手中收集算力的好處在於:1)散戶的闲置算力顯性成本較低,能提供更加經濟的算力資源;2)網絡的可擴展性和去中心化程度更高,增強了系統的彈性和穩健性。而缺點在於,散戶資源分布廣泛且不統一,管理和調度變得復雜,增加了運維難度。並且依靠散戶算力去形成初步的網絡效應會更加困難(更難kickstart)。最後,散戶的設備可能存在更多的安全隱患,會帶來數據泄露和算力被濫用的風險。
算力消費者
從算力消費者來講,Aethir、io.net、Gensyn的目標客戶主要是企業。對於B端客戶來說,AI和遊戲實時渲染需要高性能計算需求。這類工作負載對算力資源的要求極高,通常需要高端 GPU 或專業級硬件。此外,B端客戶對算力資源的穩定性和可靠性要求很高,因此必須提供高質量的服務級別協議,確保項目正常運行並提供及時的技術支持。同時,B端客戶的遷移成本很高,如果去中心化網絡沒有成熟的SDK能夠讓項目方快速deploy(比如Akash Network需要用戶自己基於遠程端口進行开發),那么很難讓客戶進行遷移。如果不是及其顯著的價格優勢,客戶遷移的意愿是非常低的。
Render Network和Akash Network主要爲散戶提供算力服務。爲C端用戶提供服務,項目需要設計簡單易用的界面和工具,爲消費者提供良好的消費體驗。並且消費者對於對價格很敏感,因此項目需要提供有競爭力的定價。
硬件類型
常見的計算硬件資源包括CPU、FPGA、GPU、ASIC和SoC等。這些硬件在設計目標、性能特性和應用領域上有顯著區別。總結來說,CPU更擅長通用計算任務,FPGA的優勢在於高並行處理和可編程性,GPU在並行計算中表現出色,ASIC在特定任務中效率最高,而SoC則集成多種功能於一體,適用於高度集成的應用。選擇哪種硬件取決於具體應用的需求、性能要求和成本考慮。我們討論的去中心化算力項目多爲收集GPU算力,這是由項目業務類型和GPU的特點決定的。因爲GPU在AI訓練、並行計算、多媒體渲染等方面有着獨特優勢。
雖然這些項目大多涉及到GPU的集成,但是不同的應用對硬件規格的要求不同,因此這些硬件有異質化的優化核心和參數。這些參數包括parallelism/serial dependencies,內存,延遲等等。例如渲染工作負載實際上更適合於消費級 GPU,而不適合性能更強的data center GPU,因爲渲染對於光线追蹤等要求高,消費級芯片如4090s等強化了RT cores,專門爲光线追蹤任務做了計算類優化。AI training和inference則需要專業級別的GPU。因此Render Network 可從散戶那裏匯集 RTX 3090s 和 4090s等消費級GPU,而IO.NET需要更多的H100s、 A100s等專業級別GPU,以滿足AI初創公司的需求。
2.2 市場定位
對於項目的定位來講,bare metal layer、orchestration layer和aggregation layer需要解決的核心問題、優化重點和價值捕獲的能力不同。
Bare metal layer 關注的是物理資源的收集和利用,Orchestration layer 關注算力的調度和優化,將物理硬件按照客戶群體的需求進行最佳優化設計。Aggregation layer是general purpose的,關注不同資源的整合和抽象。從價值鏈來講,各個項目應該從bare metal層起,努力向上進行攀升。
從價值捕獲的角度來講,從bare metal layer、orchestration layer 到aggregation layer,價值捕獲的能力是逐層遞增的。Aggregation layer能夠捕獲最多的價值,原因在於aggregation platform能夠獲得最大的網絡效應,還能直接觸及最多的用戶,相當於去中心化網絡的流量入口,從而在整個算力資源管理棧中佔據最高的價值捕獲位置。
相應的,想要構建一個aggregation platform的難度也是最大的,項目需要綜合解決技術復雜性、異構資源管理、系統可靠性和可擴展性、網絡效應實現、安全性和隱私保護以及復雜的運維管理等多方面的問題。這些挑战不利於項目的冷啓動,並且取決於賽道的發展情況和時機。在orchestration layer還未發展成熟喫下一定市場份額時,做aggregation layer是不太現實的。
目前,Aethir、Render Network、Akash Network和Gensyn都屬於Orchestration layer,他們旨在爲特定的目標和客戶群體提供服務。Aethir目前的主營業務是爲雲遊戲做實時渲染,並爲B端客戶提供一定的开發和部署環境和工具; Render Network主營業務是視頻渲染,Akash Network的任務是提供一個類似於淘寶的交易平台,而Gensyn深耕於AI training領域。io.net的定位是Aggregation layer,但目前io實現的功能還離aggregation layer的完整功能還有一段距離,雖然已經收集了Render Network和Filecoin的硬件,但對於硬件資源的抽象和整合還未完成。
2.3 硬件設施
目前,不是所有項目都公布了網絡的詳細數據,相對來說,io.net explorer的UI做的是最好的,上面可以看到GPU/CPU數量、種類、價格、分布、網絡用量、節點收入等等參數。但是4月末時io.net的前端遭到了攻擊,由於io沒有對 PUT/POST 的接口做 Auth,黑客篡改了前端數據。這爲其他項目的隱私、網絡數據可靠性也敲響了警鐘。
從GPU的數量和model來說,作爲聚合層的io.net收集的硬件數量理應是最多的。Aethir緊隨其後,其他項目的硬件情況沒有那么透明。從GPU model上可以看到,io既有A100這樣的專業級GPU,也有4090這樣的消費級GPU,種類繁多,這符合io.net aggregation的定位。io可以根據具體任務需求選擇最合適的GPU。但不同型號和品牌的GPU可能需要不同的驅動和配置,軟件也需要進行復雜的優化,這增加了管理和維護的復雜性。目前io各類任務分配主要是靠用戶自主選擇。
Aethir發布了自己的礦機,五月時,高通支持研發的Aethir Edge正式推出。它將打破遠離用戶的單一集中化的GPU集群部署方式,將算力部署到邊緣。Aethir Edge將結合H100的集群算力,共同爲AI場景服務,它可以部署訓練好的模型,以最優的成本爲用戶提供推理計算服務。這種方案離用戶更近,服務更快速,性價比也更高。
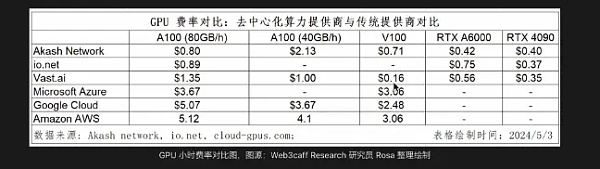
從供給和需求來看,以Akash Network爲例,其統計數據顯示,CPU總量約爲16k,GPU數量爲378個,按照網絡租賃需求,CPU和GPU的利用率分別是11.1%和19.3%。其中只有專業級GPU H100的租用率是比較高的,其他的model大多處於闲置狀態。其他網絡面臨的情況大體與Akash一致,網絡總體需求量不高,除了如A100、H100等熱門芯片,其他算力大多處於闲置的狀態。
從價格優勢來看,與除雲計算市場巨頭而言,與其他傳統服務商相比成本優勢並不突出。
2.4 財務表現
不管token model如何設計,一個健康的tokenomics都需要滿足以下幾個基本條件:1)用戶對於網絡的需求需要體現在幣價上,也就是說代幣是可以實現價值捕獲的;2)各個參與者,不管是开發者、節點、用戶都需要得到長期的公平的激勵;3)保證去中心化的治理,避免內部人士過度持有;4)合理的通脹和通縮機制和代幣釋放周期,避免大幅波動的幣價影響網絡的穩健型和持續性。
如果把代幣模型籠統地分爲BME(burn and mint equilibrium)和SFA(stake for access),這兩種模式的代幣通縮壓力來源不同:BME模型在用戶購买服務後會燃燒代幣,因此系統的通縮壓力是由需求決定的。而SFA要求服務提供者/節點質押代幣以獲得提供服務的資格,因此通縮壓力是由供給帶來的。BME的好處在於更加適合用於非標准化商品。但如果網絡的需求不足,可能面臨着持續通脹的壓力。各項目的代幣模型在細節上有差異,但總體來說,Aethir更偏向於SFA,而io.net,Render Network和Akash Network更偏向於BME,Gensyn尚未可知。
從收入來看,網絡的需求量會直接反映在網絡整體收入上(這裏不討論礦工的收入,因爲礦工除了完成任務所獲的報酬還有來自於項目的補貼。)從公开的數據上來看io.net的數值是最高的。Aethir的收入雖然還未公布,但從公开信息來看,他們宣布已經與很多B端客戶籤下了訂單。
從幣價來說,目前只有Render Network和Akash Network進行了ICO。Aethir和io.net也在近期發幣,價格表現需要再觀察,在這不做過多討論。Gensyn的計劃還不清楚。從發幣的兩個項目以及同一個賽道但沒有包含在本文討論範圍內的已經發幣的項目,綜合來講,去中心化算力網絡都有非常亮眼的價格表現,一定程度體現了巨大的市場潛力和社區的高期望。
2.5 總結
去中心化算力網絡賽道總體發展很快,已經有很多項目可以依靠產品服務客戶,並產生一定收入。賽道已經脫離了純敘事,進入可以提供初步服務的發展階段。
需求疲軟是去中心化算力網絡所面臨的共性問題,長期的客戶需求沒有被很好地驗證和挖掘。但需求側並沒有過多影響幣價,已經發幣的幾個項目表現亮眼。
AI是去中心化算力網絡的主要敘事,但並不是唯一的業務。除了應用於AI training和inference之外,算力還可被用於雲遊戲實時渲染,雲手機服務等等。
算力網絡的硬件異質化程度較高,算力網絡的質量和規模需要進一步提升。
對於C端用戶來說,成本優勢不是十分明顯。而對於B端用戶來說,除了節約成本之外,還需考慮服務的穩定性、可靠性、技術支持、合規和法律支持等等方面,而Web3的項目普遍在這些方面做得不夠好。
3 Closing thoughts
AI的爆發式增長帶來的對於算力的巨量需求是毋庸置疑的。自 2012 年以來,人工智能訓練任務中使用的算力正呈指數級增長,其目前速度爲每3.5個月翻一倍(相比之下,摩爾定律是每18個月翻倍)。自2012 年以來,人們對於算力的需求增長了超過300,000倍,遠超摩爾定律的12倍增長。據預測,GPU市場預計將在未來五年內以32%的年復合增長率增長至超過2000億美元。AMD的估計更高,公司預計到2027年GPU芯片市場將達到4000億美元。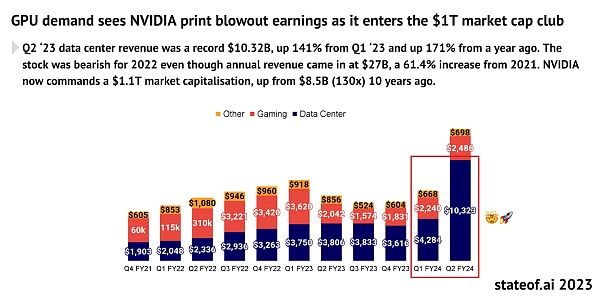
圖片來源: https://www.stateof.ai/
因爲人工智能和其他計算密集型工作負載(如AR/VR渲染)的爆發性增長暴露了傳統雲計算和領先計算市場中的結構性低效問題。理論上去中心化算力網絡能夠通過利用分布式闲置計算資源,提供更靈活、低成本和高效的解決方案,從而滿足市場對計算資源的巨大需求。因此,crypto與AI的結合有着巨大的市場潛力,但同時也面臨與傳統企業激烈的競爭、高進入門檻和復雜的市場環境。總的來說,縱觀所有crypto賽道,去中心化算力網絡是加密領域中最有希望獲得真實需求的的垂直領域之一。
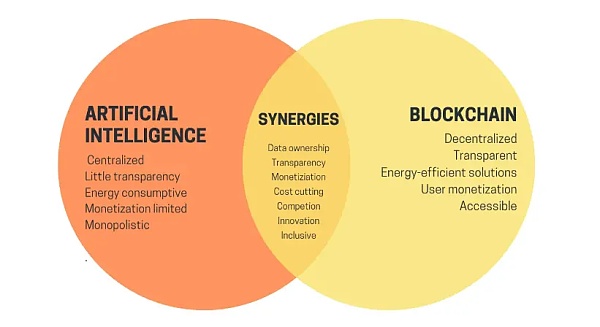
圖片來源:https://vitalik.eth.limo/general/2024/01/30/cryptoai.html
前途是光明的,道路是曲折的。想要達到上述的愿景,我們還需要解決衆多的問題與挑战,總結來說:現階段如果單純提供傳統的雲服務,項目的profit margin很小。從需求側來分析,大型企業一般會自建算力,純C端开發者大多會選擇雲服務,真正使用去中心化算力網絡資源的中小型企業是否會有穩定需求還需要進一步挖掘和驗證。另一方面,AI是一個擁有極高上限和想象空間的廣闊市場,爲了更廣闊的市場,未來去中心化算力服務商也需要向模型/AI服務進行轉型,探索更多的crypto + AI的使用場景,擴大項目能夠創造的價值。但目前來說,想要進一步發展到AI領域還存在很多問題和挑战:
價格優勢並不突出:通過之前的數據對比可以看出,去中心化算力網絡的成本優勢並沒有得到體現。可能的原因在於對於需求大的專業芯片H100、A100等,市場機制決定了這部分硬件的價格不會便宜。另外,去中心化網絡雖然能收集闲置的算力資源,但去中心化帶來的規模經濟效應的缺乏、高網絡和帶寬成本以及極大的管理和運維的復雜性等隱形成本會進一步增加算力成本。
AI training的特殊性:利用去中心化的方式進行AI trainning在現階段有着巨大的技術瓶頸。這種瓶頸從GPU的工作流程當中可以直觀體現,在大語言模型訓練中,GPU首先接收預處理後的數據批次,進行前向傳播和反向傳播計算以生成梯度。接下來,各GPU會聚合梯度並更新模型參數,確保所有GPU同步。這個過程將不斷重復,直到訓練完成所有批次或達到預定輪數。這個過程中涉及到大量的數據傳輸和同步。使用什么樣的並行和同步策略,如何優化網絡帶寬和延遲,降低通訊成本等等問題,目前都還未得到很好的解答。現階段利用去中心化算力網絡對AI進行訓練還不太現實。
數據安全和隱私:大語言模型的訓練過程中,各個涉及數據處理和傳輸的環節,比如數據分配、模型訓練、參數和梯度聚合都有可能影響數據安全和隱私。並且數據隱私幣模型隱私更加重要。如果無法解決數據隱私的問題,就無法在需求端真正規模化。
從最現實的角度考慮,一個去中心化算力網絡需要同時兼顧當下的需求發掘和未來的市場空間。找准產品定位和目標客群,比如先瞄准非AI或者Web3原生項目,從比較邊緣的需求入手,建立起早期的用戶基礎。同時,不斷探索AI與crypto結合的各種場景,探索技術前沿,實現服務的轉型升級。
參考文獻
https://www.stateof.ai/
https://vitalik.eth.limo/general/2024/01/30/cryptoai.html
https://foresightnews.pro/article/detail/34368
https://app.blockworksresearch.com/unlocked/compute-de-pi-ns-paths-to-adoption-in-an-ai-dominated-market?callback=%2Fresearch%2Fcompute-de-pi-ns-paths-to-adoption-in-an-ai-dominated-market
https://research.web3caff.com/zh/archives/17351?ref=1554
 打开金色財經App 閱讀全文
打开金色財經,閱讀體驗更佳
金色財經 > YoubiCapitai > 生於邊緣:去中心化算力網絡如何賦能Crypto與AI?
免責聲明: 金色財經作爲开放的資訊分享平台,所提供的所有資訊僅代表作者個人觀點,與金色財經平台立場無關,且不構成任何投資理財建議。
打开金色財經App 閱讀全文
打开金色財經,閱讀體驗更佳
金色財經 > YoubiCapitai > 生於邊緣:去中心化算力網絡如何賦能Crypto與AI?
免責聲明: 金色財經作爲开放的資訊分享平台,所提供的所有資訊僅代表作者個人觀點,與金色財經平台立場無關,且不構成任何投資理財建議。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。