一條長推文在人工智能愛好者中迅速傳播,重新探討了長達數十年的,關於人工智能如何最好發展的辯論。

那些不成熟、分散的开源人工智能模型,能否與OpenAI強大的GPT-4等資金充裕的專有模型相抗衡?這個經常被提出的問題在一位前谷歌人工智能研究員,在推特上表態後引發了激烈的辯論。
Galileo AI的聯合創始人Arnaud Benard向开源模型發起挑战,稱:“如果你認爲今年开源模型能贏過GPT-4,你就錯了。”他提到了OpenAI的人才和資源,以及GPT-4作爲一個產品的強大性質,超越了一個大語言模型,他斷言开源項目可能會在從挑战者,轉變爲人工智能冠軍的過程中遇到困難。
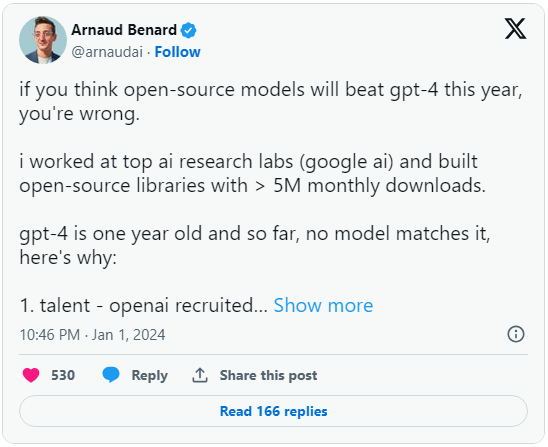
毫不奇怪,Benard的推文引發了從激烈支持到激烈反對的各種反應。
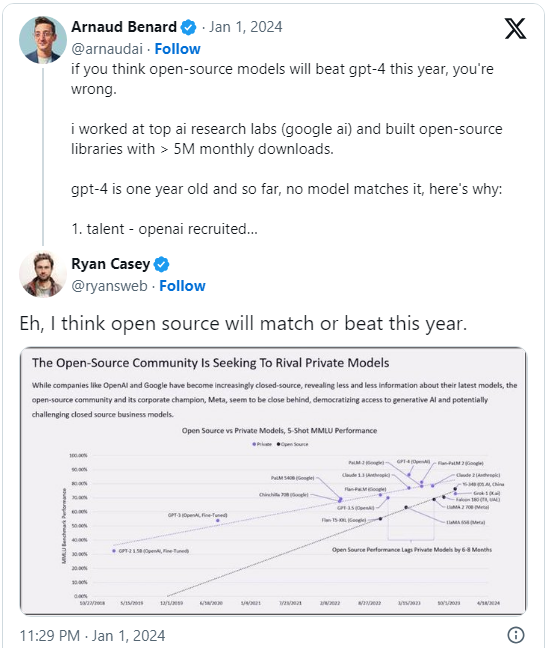
AI愛好者Ryan Casey,撰寫《Beyond The Yellow Woods》新聞通訊的知名人物,對开源人工智能潛力持更樂觀態度,表示:“开源將在今年匹敵甚至超越專有模型”,根據他的估算,“如果有需求,就會有創新。”
另一方面,AI战略家Jeremi Traguna指出:“OpenAI的模型在不斷演進”,並補充道,“开源模型將難以跟上速度,以在目標處於被擊中位置的時候追上它。” 換句話說,盡管在GPT-4時代,开源模型可能正在迎頭趕上GPT-3.5,但在我們擁有與GPT-4.5 Turbo相媲美的通用大語言模型時,可能已經出現了GPT-5。
技術分析師Jon Howells認爲,資源並不是區分开源和閉源大語言模型的唯一標准。
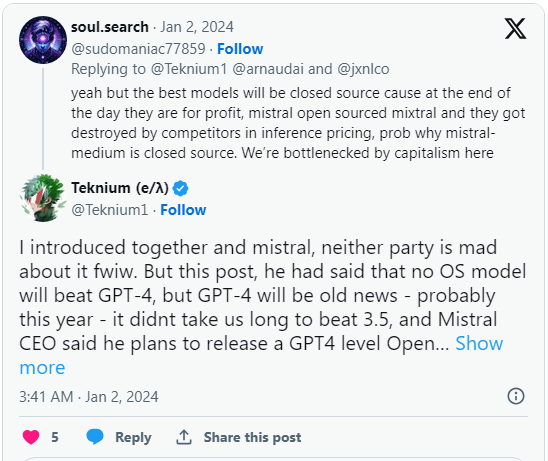
他寫道:“Mistral擁有巨額資金,一支出色的團隊,並且最近發布了一款超越GPT-3.5的开源模型。” 他表示,“他們或類似的公司將在今年年底發布一款GPT-4級別的开源模型。” 法國初創公司Mistral AI在發布其Mixtral LLM後贏得了認可,該模型在許多用例中的性能優於GPT-3.5。
在一場討論中,Nous Research的聯合創始人“Teknium”提出了一點重要但哲學性的觀點。他說:“OS(开源)中的每一項能力提升都是一個永久的東西,永遠不會被拿走,可以永遠可靠地使用。” 基本上,只要在开源人工智能技術中有一些進展,沒有公司可以限制其訪問。
开源還是封閉?無休止的辯論
开源與封閉的爭論讓人想起了早期的操作系統之爭,就像Windows和Linux之間的战鬥。ML School的Santiago Pino寫道,專有的人工智能模型可能會像Windows一樣贏得一般消費者,但开源軟件提供了可以極大用於企業用戶的定制和控制。
Pino強調了許多公司开始嘗試ChatGPT,然後遷移到开源模型的情況,他們可以對其進行微調和定制以滿足其特定的需求和數據合規性要求。他在Bernard的推文傳播前幾天在推特上表示:“封閉、專有的模型可能會贏得個人,但大多數公司不想將他們的數據發送到Microsoft或Google。因爲他們的目的是想要控制开源模型。”
在Bernard的推文辯論中,軟件开發公司Sciumo Inc.也強調了开源模型的專業潛力:“开源模型將在關鍵領域競爭:具有領域專業數據和專業知識的領域的特定問題(OpenAI)將無法解決。”在特定領域的問題處理,擁有(OpenAI)所不具備的特定領域數據和專業知識。
計算機工程師Furkan Gözükara,以其YouTube頻道SECourses而聞名,也持更爲復雜的立場之一。他在接受媒體採訪時同意了Bernard的觀點,稱“只有在特定任務上,开源大語言模型才能超越OpenAI。”
以 Gözükara “一家公司對(自己的)文件進行大語言模型訓練”爲例。是的,OpenAI有能力根據具體的指示和文件定制GPT,但將敏感數據處理給第三方始終是一個擔憂。最近曝光的個性化GPT向第三方用戶泄露敏感數據的情況就驗證了這一擔憂。
Meta的AI开發負責人、堅定的开源支持者Yan Lecun一再表示:“开源人工智能基礎模型將消滅封閉和專有的人工智能模型。” 另一家人工智能巨頭Google也認識到开源人工智能帶來的威脅:“开源模型更快、更可定制、更私密,而且在性能上更有競爭力,”2023年泄露的Google備忘錄中如此說道。
目前尚不清楚开源模型是否會在今年匹敵或超越GPT-4及其未來版本。然而,雙方專家的觀點揭示了一個有趣的緊張關系。封閉源模型在資源和迅速迭代方面可能具有優勢,但开源工具正在迅速發展,提供永久的功能和可定制性。目前,人工智能社區可以觀察競爭的發展,並享受使用最先進技術的好處。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。