 免責聲明: 內容不構成买賣依據,投資有風險,入市需謹慎!
免責聲明: 內容不構成买賣依據,投資有風險,入市需謹慎!
AI 的未來:去中心化人工智能

 TechubNews
個人專欄
剛剛
TechubNews
個人專欄
剛剛
 關注
關注
來源:AI 的未來:去中心化人工智能
原文標題:《AI in Web3: Navigating AI’s Future with Web3》
撰文:DWF Labs Research
編譯:Carl,Techub News

在過去的一年裏,OpenAI 推出的 ChatGPT 3.5 讓人工智能成爲討論的焦點,ChatGPT 展示出了人工智能巨大的經濟潛力,同時也引發了全球對其帶來的影響和風險等方面的討論。
隨着樂觀情緒的增長,懷疑也隨之而來。潛在的後果开始給監管機構敲響警鐘。人工智能的迅速崛起和模糊的監管框架,與處於早期的加密貨幣領域相呼應。兩個行業似乎就像兩條平行线一樣,去中心化的 Web3 與人工智能潛在的中心化力量形成互補。在今年的第一季度裏,幾乎所有 Web3 VC 都在討論人工智能的變革潛力(有一次,我都在疑惑自己參加的活動主題到底是 Web3 還是 AI)。在這一年中,我們還看到一些風險投資機構轉向 AI 或將其納入其投資任務。

來源:web3 VC space
現在,隨着時間的推移,對 AI 的炒作逐漸消退,DWF Ventures 希望以公正的視角來重新審視人工智能領域。本文概述了人工智能的演變以及它如何達到目前的流行程度。然而,本文的敘述有一個明顯的不同:將從普遍關注的人工智能如何影響 Web3 轉向探索相反的方向——Web3 如何影響人工智能。在本文中,我們深入研究了去中心化和 Web3 如何充當催化劑,解決人工智能當前面臨的挑战。
AI 發展史和 ChatGPT 的突破
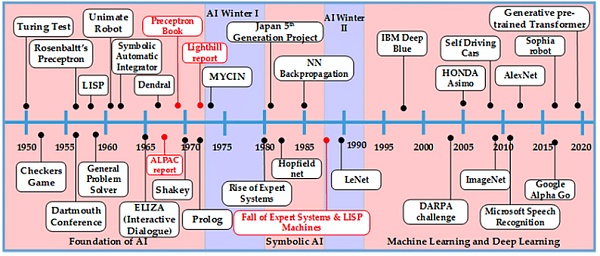
資料來源:(Khan、Pasha & Masud,2021)
人工智能的歷史可以追溯到 20 世紀 30 年代。1950 年代的圖靈機,包括圖靈測試,正式奠定了人工智能的基礎。盡管早期很樂觀,但由於計算障礙和無法滿足實時需求,人們在 20 世紀 70 年代對人工智能的熱情有所下降,迎來了「人工智能冬天」。20 世紀 80 年代,專家系統利用知識數據庫模擬人類專業知識,又一次重振了人工智能,並出現了聯結主義的復興和循環神經網絡的興起。
然而,專家系統在知識獲取和實時分析方面遇到了挑战,這導致人工智能在 20 世紀 90 年代又一次衰落。此後經過多年的發展,人工智能領域取得了很大的進展,已擴展到機器學習、自然語言處理、計算機視覺、語音識別等不同的技術領域。這些發展使得人工智能從簡單的解決問題發展到復雜應用領域的深度學習。
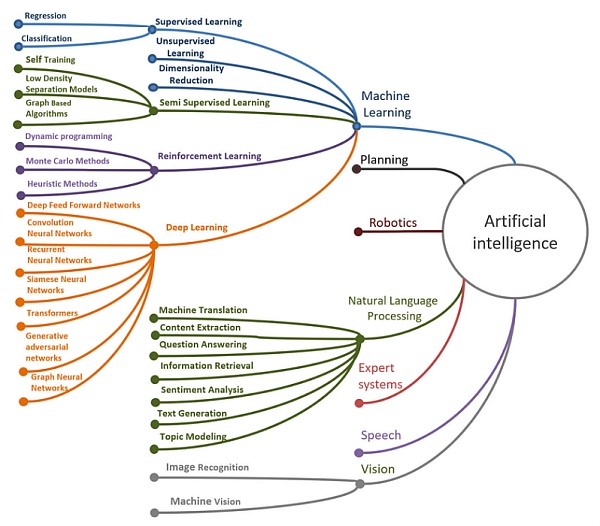
資料來源:Mukhamediev et al.,2022
在發展過程中,我們看到了人工智能各個子領域的融合。在這些領域中,機器學習和大語言模型(LLM)領域取得了重大進展。Ashish Vaswani 等人的論文啓發了基於 transformer 的生成式預訓練模型(GPT)。此後,大量的 GPT 出現,例如「BERT」GPT 和 OpenAI 團隊的GPT。ChatGPT 之後,還出現了 Falcon 和 LLaMA2 等开源替代方案,加劇了开發更接近 AGI(通用人工智能)的下一代 GPT 的競爭。
GPT 的炒作幫助 AI 從學術界進入了數十億人的視野。ChatGPT 發布後 2 個月內,創下了每周活躍用戶數超過 1 億的最快記錄。麥肯錫最近的一項研究顯示,目前,科技行業約 51% 的專業人士在工作中使用 AI。
人工智能的社會認知和限制
Vitalik 最近進行的一項民意調查顯示,人們擔心出現 AI 壟斷版本,普遍傾向於推遲 AI 進步。
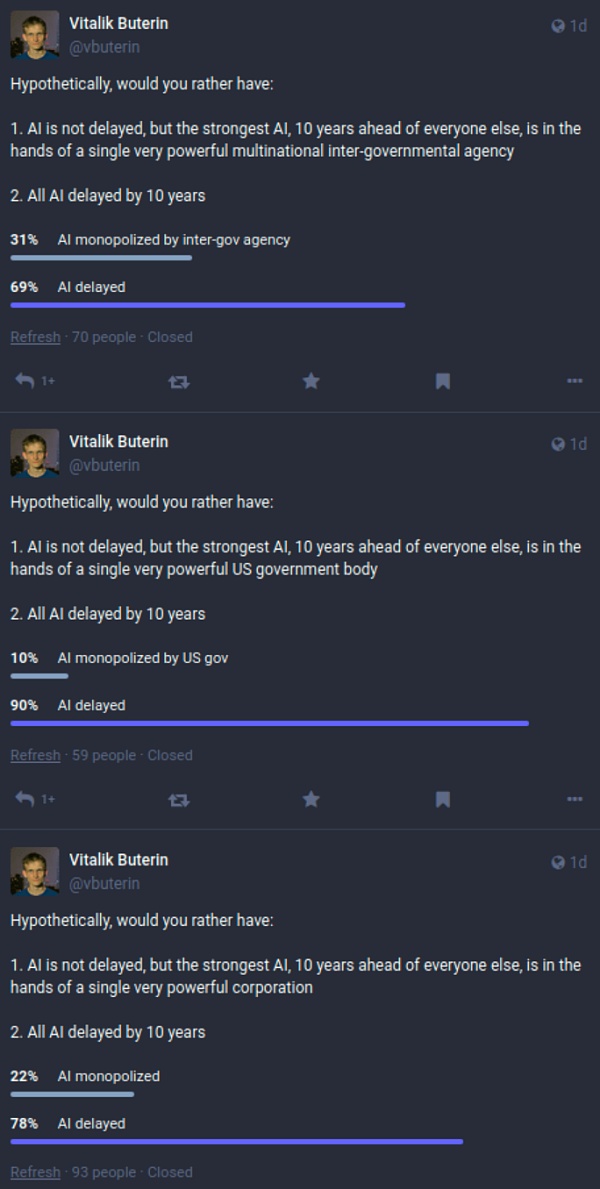
資料來源:My techno-optimism
ChatGPT 讓 AI 受到的關注度激增,然而,大多數人沒有意識到,雖然 GPT 模仿了人類交互,但它還不是 AGI。
GPT 每次在輸出時,都會發生統計上的偏差,無法保證一致性和事實准確性。GPT 還面臨其他限制,其最突出的缺點是無法進行邏輯推理,尤其是在數學方面。
GPT 的局限性
描述
文本合成的局限性
- 文檔級的語義重復
- 長段落中的連貫性
- 自相矛盾和不合邏輯的句子
無法完成離散語言任務
- 不符合“物理常識”
- 在比較單詞用法和確定句子的含義等方面存在困難
結構和算法限制
- 在特定情境下的學習表現差
- 在“比較”任務上表現差
缺乏雙向架構
- 缺乏雙向架構和其他訓練目標,可能會影響任務效果
預訓練目標的局限性
- 在不考慮 Token 重要性的情況下,自我監督的預測可能會達到極限
樣本預訓練效率低下
- 與人類成長相比,大模型預訓練的效率極低
小樣本學習中的歧義
- 小樣本學習是否在推理時“從頭开始”學習新任務,還是識別預訓練期間學到的任務方面存在模糊性
不切實際的模型規模和推理
- 像 GPT-3 這樣的大模型價格昂貴且不方便使用
大模型的潛在濫用
- 在錯誤信息、垃圾郵件、網絡釣魚等活動中可能被濫用
由於投入巨大而缺乏公平性或導致偏見
- 訓練數據中的偏差可能會導致大模型生成的內容強化刻板印象或偏見
高能源消耗
- 大規模預訓練是能源密集型的,需要大量的計算資源
資料來源:Limitations of GPT in Language Models are Few-Shot Learners
鑑於圍繞人工智能的無數擔憂和有效管理大型人工智能模型的挑战,Web3 成爲緩解這些挑战的潛在途徑。Web3 固有的去中心化和分布式原則,有助於解決人工智能系統當前面臨的問題。
去中心化人工智能
人工智能功能集中在中心化系統中,引起了人們對數據訪問、模型關聯性和整體可持續性的擔憂。中心化人工智能系統面臨重大障礙,特別是對於具有排他性的專有大型數據集。
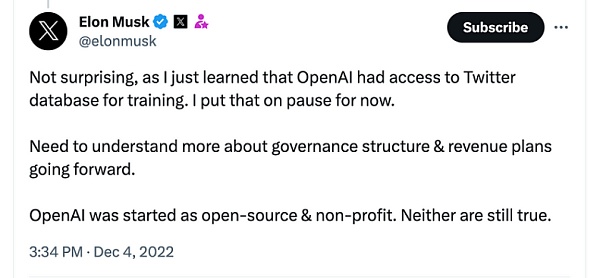
如上圖,馬斯克在 X 上表示:「這並不奇怪,因爲我剛剛得知 OpenAl 可以訪問 Twitter 數據庫進行訓練。我暫停了它。需要更多地了解未來的治理結構和收入計劃。OpenAl 最初是开源和非營利性的,現在來看兩者都不是。」
此後,X.com 开始對查詢數據收費,並限制了用戶的每日帖子瀏覽量。不久後,X.com 的 GPT「Grok」發布,允許用戶實時訪問 X.com 的數據。這形成了經濟屏障,並引出人工智能的可訪問性和包容性問題。
此外,如果沒有持續的數據更新,已發布的大模型很快會過時,這對保持實用性和准確性構成了巨大的挑战。目前,ChatGPT 3.5 的訓練數據是截至 2022 年 1 月的信息,而 Llama 2 則是在 2023 年 1 月至 2023 年 7 月之間。
爲了應對這些挑战,去中心化人工智能(DAI) 成爲一種有前途的範例,爲中心化的局限性提供了潛在的解決方案。
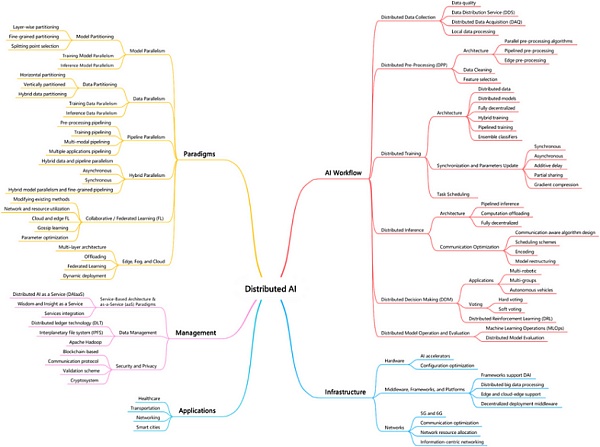
資料來源:(Janbi 等人,2023)
DAI 提供了一種替代路徑,以應對中心化模型固有的挑战。Janbi 等人最近的一篇論文進行了全面的分析,並將 DAI 分爲以下五個主要領域。
領域
描述
Web3 的影響
人工智能工作流程
大模型的系統化开發與訓練
DAI 簡化了這一過程並使之民主化,使其更易於訪問和協作。
人工智能基礎設施
科技基礎設施,包括硬件、軟件和網絡。
去中心化物理基礎設施網絡(DePIN) 可以爲計算資源提供更有效的路徑。
範式
指導人工智能系統設計和實施的框架
引入新的範式,例如協作或聯合學習,使計算更加貼近用戶。
管理
確保有效資源分配和項目協調的機制
需要引入衆多復雜的利益相關者,形成創新的協調和激勵機制。
應用領域
爲用戶量身定制的人工智能技術應用。
利用去中心化提高效率、透明度和道德規範。
資料來源:(Janbi 等人,2023)+ DWF Ventures
DAI 的挑战
DAI 爲人工智能帶來了令人興奮的轉變和衆多優勢,然而,承認仍然存在的挑战至關重要。
好處
挑战
解決方案的多樣性
不同專家系統之間的協作,每個專家系統都貢獻獨特的專業知識來解決超出個人能力的復雜問題
協調性差
確保利益相關者一致和合作具有挑战性,因爲每個人都可能在知識不完整的情況下進行操作,從而導致潛在的不一致
模塊化、可重復使用和高效率
模塊化設計允許在各種應用程序中重復使用小型專家系統,通過專用處理器並行執行任務來提高效率
利益相關者知識不完整和不一致
分布式責任導致利益相關者只擁有部分知識,這可能會導致大家不一致,從而影響整個系統的可靠性
復雜性控制與對分布式問題的適應
分解處理分布式系統的任務
战略規劃挑战
不同利益相關者難以就特定目標達成一致
無集中攻擊點
通過避免中心化瓶頸的方式來增強響應能力,在數據或系統出現問題時弱化故障
信息收集的復雜性
由於無休止的溝通和動態變化,利益相關者必須決定如何以及何時更新其狀態。
處理大規模問題
有潛力解決中心化系統無法解決的大規模問題。
資料來源:(Eduardo, L., & Hern, C.,1988) + DWF Ventures
結論
總之,DAI 正以巨大的潛力展开。由於供應商和用戶有限,开源替代方案面臨困難,而 ChatGPT API 爲大衆市場提供了實用且經濟的選擇,提供了易用性和可靠性。
然而,考慮到壟斷的通用人工智能的潛在後果,個人應該重新權衡其選擇和行動中的便利性和去中心化。在更廣泛的範圍內,Web3 和 AI 社區的創新者可以重新定義 AI 工作流程、重新構建基礎設施、採用創新範式、高效管理以及开發符合去中心化原則的應用程序來應對挑战。當我們繼續沿着這條道路前進時,協作、包容性和道德規範將成爲塑造真正造福人類的 DAI 格局的關鍵。
 打开金色財經App 閱讀全文
打开金色財經,閱讀體驗更佳
金色財經 > TechubNews > AI 的未來:去中心化人工智能
免責聲明: 金色財經作爲开放的資訊分享平台,所提供的所有資訊僅代表作者個人觀點,與金色財經平台立場無關,且不構成任何投資理財建議。
打开金色財經App 閱讀全文
打开金色財經,閱讀體驗更佳
金色財經 > TechubNews > AI 的未來:去中心化人工智能
免責聲明: 金色財經作爲开放的資訊分享平台,所提供的所有資訊僅代表作者個人觀點,與金色財經平台立場無關,且不構成任何投資理財建議。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。