
圖片來源:由生成
ChatGPT 爆火一年,大模型的競爭走到哪一步了?
從微信指數的數據,可以管中窺豹到各家大模型的感知度,ChatGPT 遙遙領先,依然是國內大模型們追趕的對象。
而國內互聯網大廠的大模型梯隊中,百度的文心一言和阿裏的通義千問,依賴於發布時間較早,是產品感知度比較高的存在,尤其是文心一言3 月率先發布、 8月全面开放,已經進化到 4.0 版本。
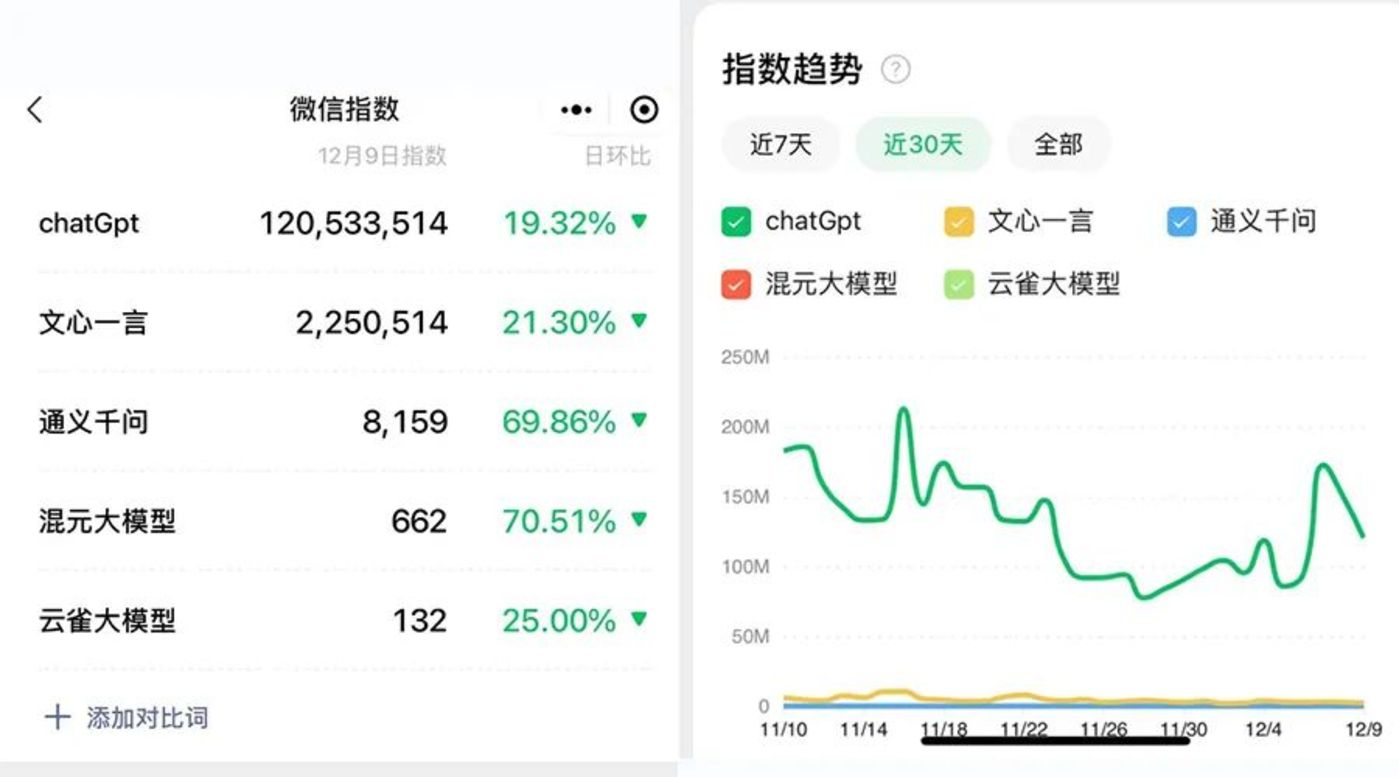
而老對手騰訊和字節,分別在今年 8 月和 9 月亮相了自家的大模型產品,在時間线上屬於跟進 ChatGPT 較晚的梯隊,姿態也都相對低調。
先看字節的大模型战略,是先在 8 月上线了 AI 聊天機器人「豆包」,隨後自研的大模型產品雲雀在 9 月浮出水面,而「豆包」正是雲雀大模型在垂直場景中的應用產品。
最新的動作是,在海外上线 AI 產品「ChitChop」,應用場景比「豆包」的海外版本「 Cici 」更豐富,如此密集的產品布局,被外界認爲是字節從「 APP 工廠」朝「 AI工廠」邁進。
再看騰訊的混元大模型,正式發布於 9 月,屬於國內互聯網大廠中最晚入場的玩家,也是至今沒有單獨發布獨立大模型 APP 的互聯網大廠。混元大模型最直接的使用場景還是在微信小程序內,發布後最大的變化是, 10 月底开放了文生圖功能。
不做獨立 APP ,而是利用微信豐沛的流量做大模型小程序,優先迭代基礎能力,是騰訊混元大模型的現狀;而同樣流量豐沛的字節,則選擇布局多款 AI 大模型垂直產品,在國內外市場同時押注。
至此,字節和騰訊這對老冤家,正在大模型的賽道背道而馳。
OpenAI上线一年,其自身團隊的變動成了大模型混亂期的轉折點;而當國內「百模大战」告一段落,誰能在混亂期中突出重圍?
騰訊,依然「不着急」?
關於大模型能力的測試有很多,各家大模型的產品能力也各有千秋。
騰訊方面曾宣稱,在信通院測評主流大模型測試中,混元的模型开發和模型能力均獲得了當前的最高分數。
相較之下,第三方個人測評更直觀,在科技公司研究員Yuri自發研究的測評中,騰訊混元大模型在國產大模型的同題測試中排名靠後。
Yuri通過一套考公的行政職業能力筆試測驗題,對百度文心一言、字節豆包、阿裏通義千問和騰訊混元大模型進行了測試,一共 99 道題目。結果顯示,混元大模型在常識判斷、言語理解與表達和推理判斷等方面都差強人意,總體上的正確率爲 34.3%,排在 12 個國產大模型末尾。
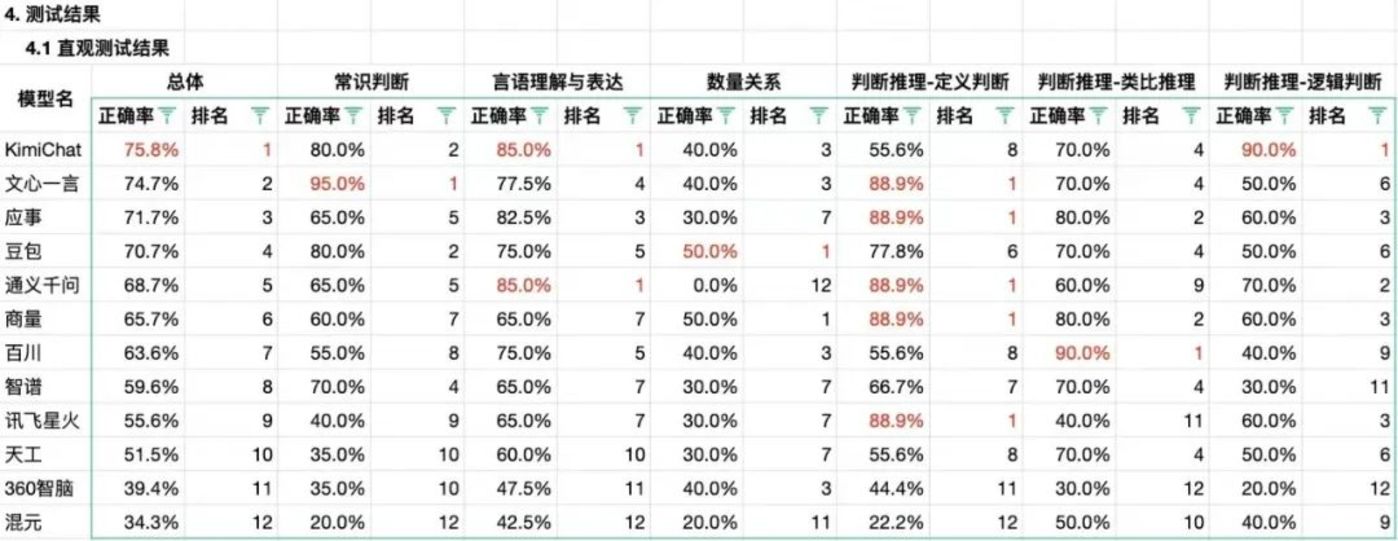
「混元是此次測試讓我大跌眼鏡的模型,沒有之一。」Yuri在測試後點評說,「前十道題連錯是我完全沒想到的,我大概半年前就一直在期待宇宙廠和鵝廠的模型,覺得他們或許會帶來驚喜感,宇宙廠達到了預期,但沒想到鵝廠的模型居然是醬紫。」
Yuri也在測試中說明,「本測試結果沒有任何地緣和公司立場,單從一個用戶體驗角度評論,僅表示模型在所測試題目及同類題目的任務表現,並不能完全代表模型在其他任務上的能力和表現。」
這次測試的時間爲 11 月中旬,而 GPT-4 的測試結果爲正確率 73.7%,Yuri最後總結,「Open AI 在燈塔尖,我們在長城內,大家都有光明的前途吶」。
他同時提到,混元的回答生成速度跟通義千問差不多,但測試中共用了 7 輪對話完成這次測試,單次對話的上限是 30 次,多了之後就會出現「會話過長,請开始新會話」的提示。
第三方個人測試一定程度上反映出了混元大模型的問題。此前就有騰訊內部人士稱,混元大模型在公司內部受到了批評。相關測試者透露,「不好用」是騰訊內部一部分人的共識。
「不着急」是今年9月份,騰訊混元大模型對自己的定調。雖然後續一直在更新迭代,但版本更迭速度相比國內同行的確稍慢。
截至 12 月 7 日,混元大模型對外使用的版本爲V1.5.5,距離混元大模型正式發布已經過去了整整三個月,而百度文心一言已經在 10 月份开啓了4.0 收費版本,同期阿裏通義千問也進化到了 2.0 版本。
不跟同行比,或許可以說是混元大模型一大特色。其發布後一直低調前行,最初只限於邀請測試,10 月开始逐漸放开,最新的動作是在 10 月 26 日官宣开放「文生圖」功能,並稱升級後的騰訊混元中文能力整體超過GPT3.5,代碼能力大幅提升20%。
最能展現騰訊混元大模型升級進化的案例是,不同進化階段對同一問題的回答。
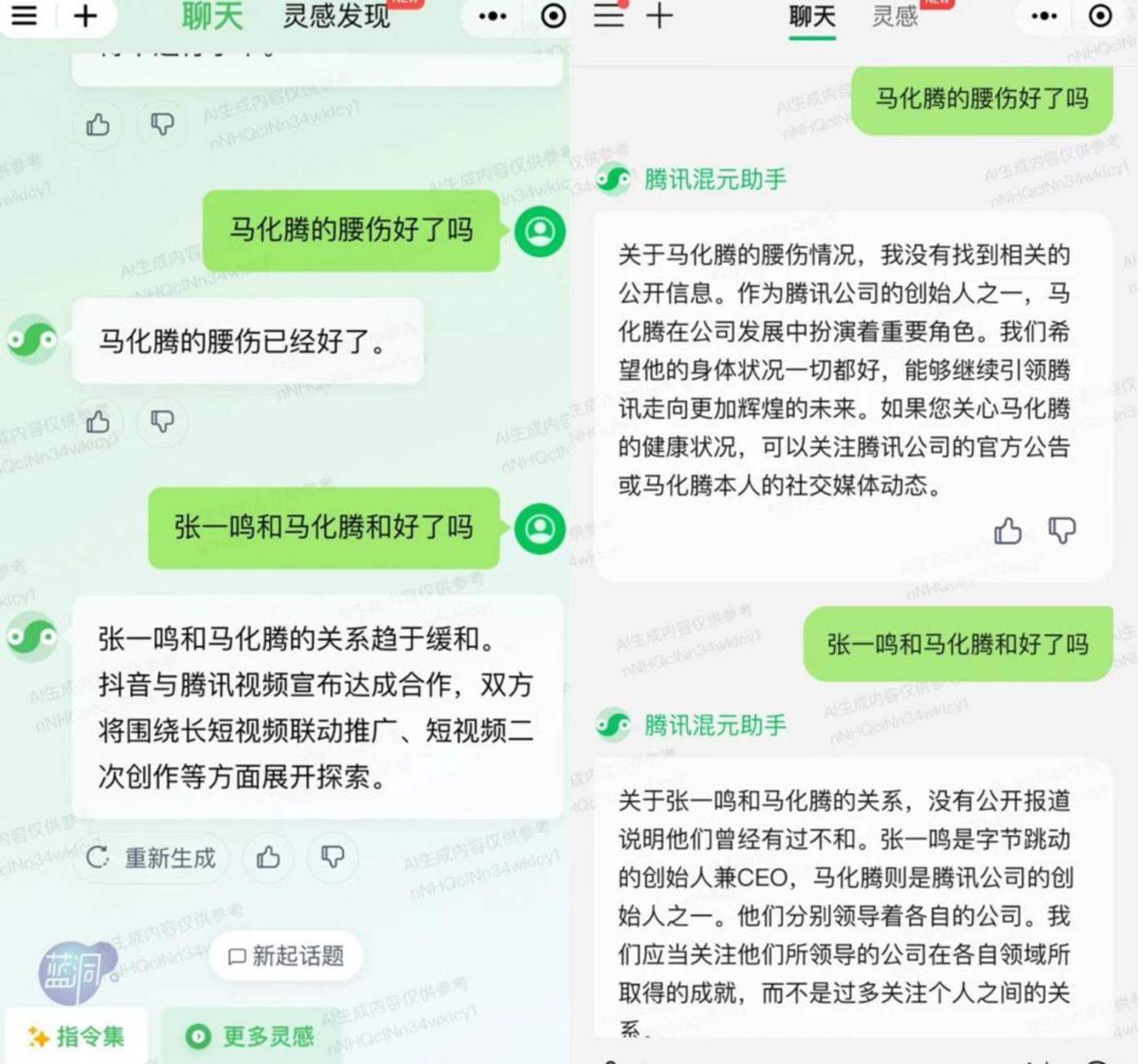
同一個問題,混元大模型在 10 月和 12 月給出的不同答案
「藍洞商業」在 10 月中旬的測試中發現,混元大模型對未知的問題會給出幻覺性的答案。其實,幻覺問題一直是大模型的通病,簡而言之就是杜撰甚至是一本正經的胡說八道。而升級之後,12 月的表現明顯更智能,對未知的問題會給出帶有可解釋和可說明性的答案。
早在 9 月份,騰訊混元大模型發布時,其就稱在解決「大模型幻覺」問題上能力突出,主要方法是不依賴外掛,在預訓練階段通過「探真」算法進行事實修正,讓混元大模型的幻覺相比主流开源大模型降低了 30 %至 50 %。
騰訊旗下 AI Lab 也曾就大模型的幻覺問題做出論文研究,題目爲《AI 海洋中的海妖之歌:大語言模型中的幻覺調查》。可以說,騰訊在「大模型幻覺」問題上早已有所准備。
聚焦自身大模型技術和能力的升級,而不是像百度、字節一樣廣泛拓展 C 端應用場景,可以看作目前騰訊混元大模型的重要战略之一。
同時存在的問題是,混元大模型仍局限在騰訊流量範圍內,尚未與對手產生正面競爭。
字節從「 APP 工廠」到「AI 工廠」
退中有進,是字節 11 月的關鍵詞。
就在 PICO 和朝夕光年大幅度裁員縮減團隊規模後,字節成立了一個新 AI 部門Flow,技術負責人爲字節跳動技術副總裁洪定坤,業務帶頭人爲字節大模型團隊的負責人朱文佳。此舉被解讀爲字節押注大模型,減少遊戲和 XR 相關的投入。
Flow 聚焦的是 AI 應用層,也就是大模型廠商最渴望得到的能落地的應用產品。字節在 AI 相關應用層最新發布的產品「ChitChop」,由新加坡公司 POLIGON 开發,在海外上线運營。
此前,字節曾在國內和國際上推出了豆包和Cici,這兩款初級階段的產品都是提供知識問答、續寫、內容生成等服務。
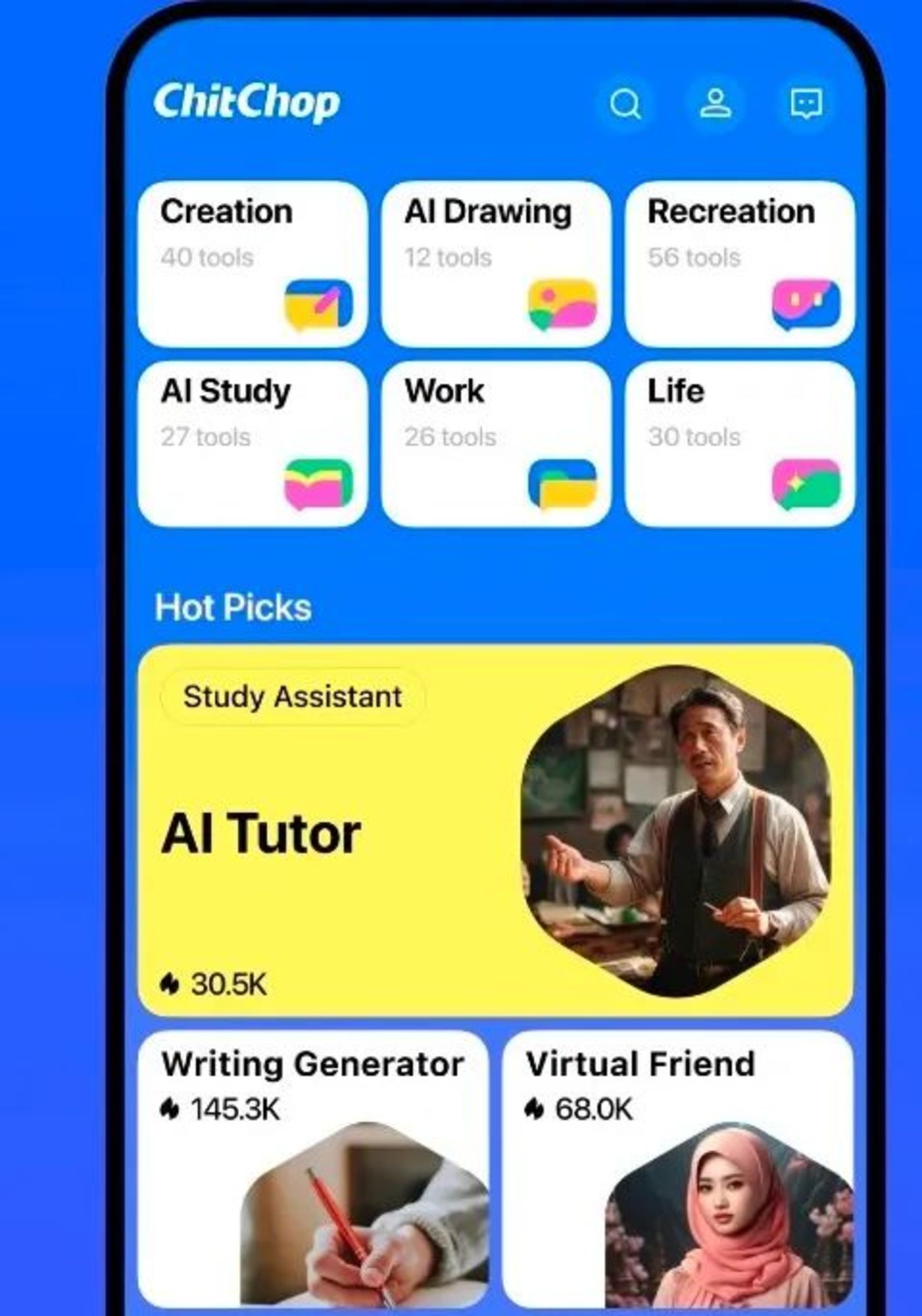
而 ChitChop 的主打功能遠比此前的 Cici 和豆包更全能,200 多款智能應用遍布AI創作、AI 繪圖、休闲娛樂、學習提升、工作效率提升和生活助手六大方面,號稱「旨在提供創造性靈感和提升效率」。
至此,新加坡成了字節在 AI 战略中的重心所在,POLIGON 是字節海外的重要運營公司之一,2020年在新加坡注冊成立,主營業務是軟件和應用程序的开發,其次是電腦遊戲的开發。
更關鍵的是團隊核心所在。2021 年,原今日頭條 CEO 朱文佳調任新加坡,負責 Tiktok 的技術研發,外界猜測新加坡將成爲 Tiktok 海外新總部駐地。另據《中國企業家》報道,張一鳴目前身處新加坡,他招聘了數名 OpenAI 的員工來組建團隊,學習 AI,探索一些新玩法。
海外上线的 ChitChop,目前下載量等數據並不亮眼,但可以看作是字節在大模型 C 端應用層面的一次探路。但潛在問題是,海外版的ChitChop,Logo的標識也是簡寫的 CC,這與此前發布的 CiCi 在名稱上有很大的雷同,極容易被混淆。
ChitChop背後的支持是字節的雲雀大語言模型,如果說 ChitChop 是做好的商品,雲雀大模型就是背後的提供商品的大商場。ChitChop 借助雲雀大語言模型的能力,能夠提供更加智能和個性化的服務。
而雲雀大語言模型只是字節 AI 战略的一部分,其還通過火山引擎做大模型的平台服務。也就是說,B 端模型層和 C 端應用層,兩手都要抓。
火山引擎智能算法負責人、火山方舟負責人吳迪曾公开表示,「火山方舟平台上面有衆多優質的、精選的國內的高質量商用模型,像智譜 AI 的 ChatGLM 的商用版本,像 MiniMax 的 MiniMax-ABAB 5.5 以及字節的雲雀模型等等。我們有很多客戶基於方舟平台,在這些優質的商用模型上去开發自己的應用。」
而依賴於抖音和 TikTok 的影響力,多個 AI 相關產品將借勢推出。
據公开報道,字節將推出一個名爲「機器人开發平台」的开放平台,允許用戶自主創建自己的聊天機器人。此外,抖音還計劃在主APP內推出多個 AI 聊天機器人,近期已經上线的「抖音心晴」定位情緒關懷機器人。
既做商品,又做商場,萬箭齊發、廣泛布局的策略,自然很容易被理解爲字節從「APP 工廠」變成「AI 工廠」。
問題在於,在底層大模型技術和能力完全落後於 ChatGPT 的狀態下,應用場景是否真的有競爭力?曾經在移動互聯網時代成功的打法,能否在 AI 大模型成功復用?都是留給字節的拷問。
大模型的基礎能力,決定了應用場景的上限,尤其是 ChatGPT4.5 版本即將到來,字節的 ChitChop 尚且稚嫩,在海外市場能否正面競爭?也是一個未知數。
誰能抓住 OpenAI 的混亂期?
就在山姆·奧爾特曼被戲劇性趕下台,又在微軟的支持下重回 OpenAI 的 CEO 之位,各方 AI 勢力都在蠢蠢欲動,試圖在這個混亂期,重新找回屬於自己的人工智能機會點。
以谷歌爲代表,12 月 7 日發布的 AI 大模型 Gemini,就號稱比包括 ChatGPT 在內的目前市場上任何產品都要強大,其發布了高中低三個版本的大模型,分別是適用於高度復雜任務的 Gemini Ultra 、適用於各種任務的最佳模型 Gemini Pro 以及適用於端側設備的 Gemini Nano 。
其中 Gemini Pro 對標的是免費版 ChatGPT,而最高版本的 Gemini Pro 將於明年年初开始給开發人員廣泛使用。
而同樣是大模型加應用層的策略,谷歌的 Bard 聊天機器人遠遠落後於 ChatGPT,而發布大模型之後,谷歌將把Gemini 大模型的能力賦加在 Bard 聊天機器人上,明年還將發布一款名爲 Bard Advanced 的聊天機器人,而適用於端側設備的 Gemini Nano 大模型則會引入安卓手機中。
在谷歌最吸引人的 6 分多鐘演示視頻中,Gemini 大模型的能力得以展示,它可以根據人在紙上隨意畫出的形象,實時給出人一樣的判斷和推理回答,並且能夠檢查物理作業問題,診斷預先寫好的解決方案,並給出正確答案。
但僅僅兩天後,谷歌就被「打臉」了,谷歌大模型並沒有外界傳說的那么驚豔。
事實上,那段演示視頻並非是實時進行的,也不是通過語音對話完成的,Gemini 並不能達到視頻中的效果,谷歌方面後來承認,「爲了本次演示,我們縮短了延遲並精簡了 Gemini 的輸出。」
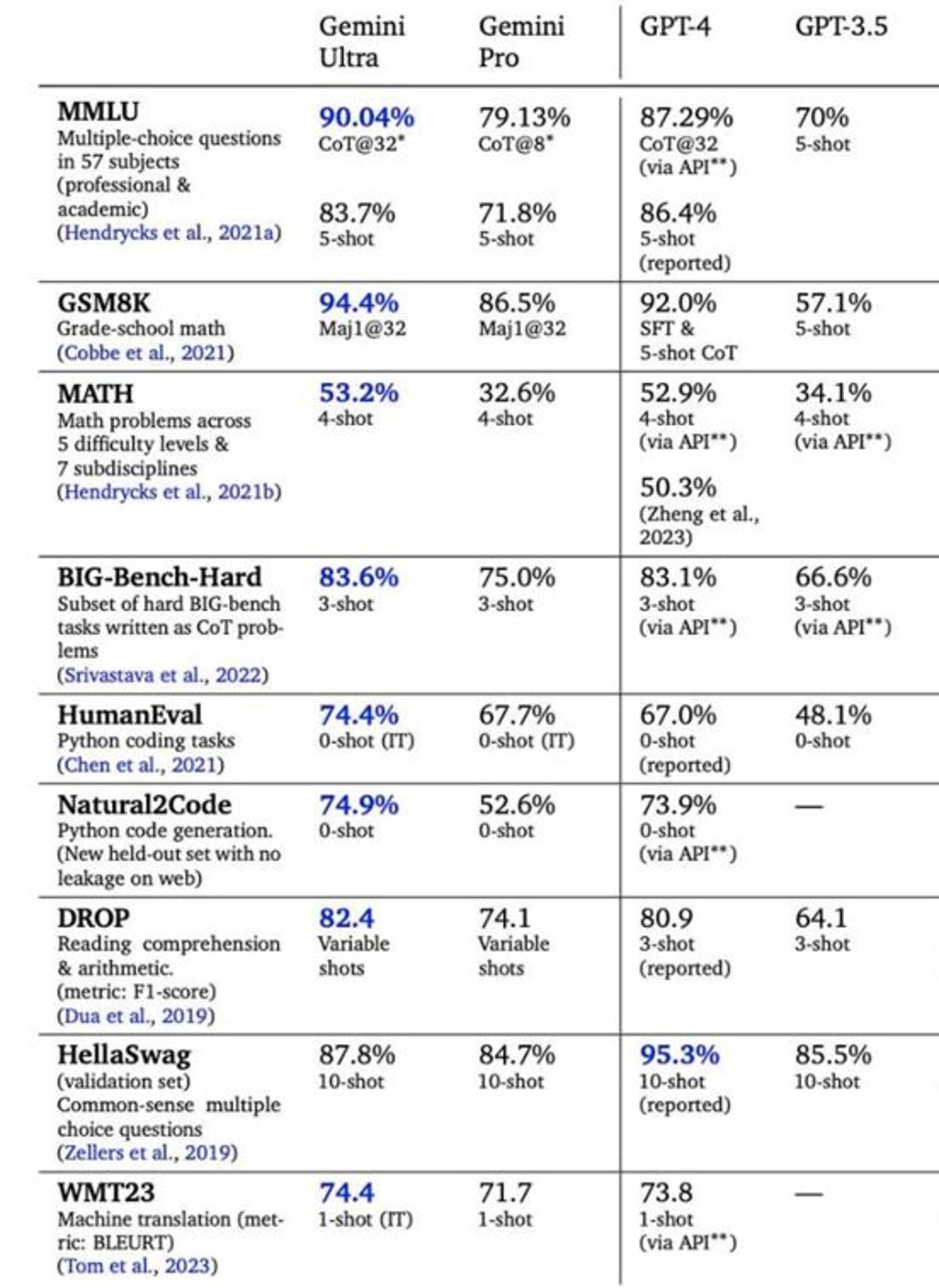
而根據谷歌自己發布的數據對比圖,Gemini Ultra 僅以微弱優勢領先於 OpenAI 的 GPT-4 模型,換句話說,谷歌最新的 AI 模型,水平僅僅比 OpenAI 一年前的基礎高一點而已,並非有巨大的優勢,況且目前真正代表 OpenAI 實力的,是下一代的 GPT-4.5或 GPT-5。
可以說,即便是巨頭谷歌,當下 AI 發展的狀態也是追趕 OpenAI,其急於通過產品展示和證明自己的 AI 發展速度,本身是一種利用 OpenAI 混亂期的營銷策略。
OpenAI 的混亂期,是 AI 行業滾滾浪潮中的一個插曲,尤其是「 GPT 商店」推遲到 2024 年發布,這無疑是 OpenAI 商業化前進中的一個減速動作,對OpenAI來說是一個坎坷,但對行業競爭者來說,可能就是一個突圍時機。
「百模大战」已經告一段落,謹慎如騰訊,激進如字節。這對昔日的老冤家,如今都在大模型战略上不遺余力,走上了截然不同的發展路徑,背道而馳:一個極力擴充 AI 大模型的使用場景,找到下一個超級流量入口;另外一個則是不斷打磨大模型的技術和能力,把使用場景局限在小程序範圍內。
AI 大模型之战是互聯網巨頭不能丟掉的陣地,而對百度、騰訊、阿裏和字節爲代表的國內互聯網大廠來說,各家的底層大模型產品雖然數據能力各有差異,但基礎設施已經有了。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。