編譯:霧月&白丁,極客web3
本文爲Nervos聯創Jan在2019年HBS Blockchain+Crypto Club Conference上的講話,主題圍繞着Layer2與Layer1之間的關系展开,明確提出模塊化區塊鏈會是正確的方向,還談及了區塊鏈數據存儲機制的問題。同時Jan也拋出了一個頗爲有趣的話題:Layer2的興起若導致Layer1飢餓,該怎么解決。
作爲最早一批支持Layer2與模塊化區塊鏈敘事的團隊,Nervos的主張在18、19年時頗具前瞻性,彼時的以太坊社區還對分片抱有不切實際的幻想,而高性能單片鏈的敘事也處於甚囂塵上的狀態,尚未被充分證僞。
但在2024年的今天,回看以太坊Layer2在實踐當中暴露出的問題,以及Solana爲代表的“高性能公鏈”在去中心化與免信任問題上的弊端,不得不說Jan在5年前的觀點很有先見之明。出於對Layer2本身的興趣,“極客web3”將Jan的講座以文字版的形式整理成文,發表於此,歡迎Nervos與以太坊、比特幣社區的Layer2愛好者們共同學習與討論。

以下爲Jan的講座原文。
Layer1和Layer2的定義
這是我對L1和L2(二層網絡)的定義,如圖。
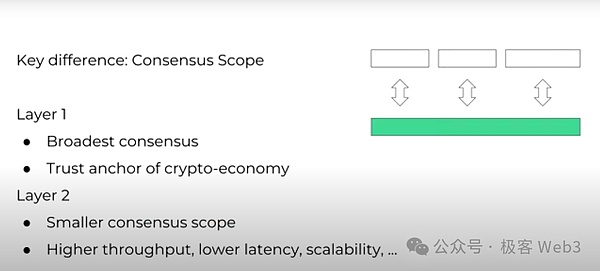
首先要強調,Nerovs只是一個努力滿足去中心化經濟需求的區塊鏈網絡,並不負責解決“所有問題”。在我們的認知裏,Layer1和Layer2的區別,關鍵在於共識的強弱。L1網絡必須具有最廣泛的共識,即“全球共識”。通過無需許可的全球共識,世界上任何人都可以參與到L1的共識過程中,最終Layer1可以作爲去中心化經濟的“錨”。從這個角度來講,我們可以把L1稱爲“共識層”。
相比之下,L2網絡的共識範圍會小一些,其參與者可能僅來自某個國家,或某個行業,甚至是某家公司或機構,亦或是範圍很小的社區。L2在共識範圍上的犧牲是一種代價,換來了其他方面的進步,比如更高的TPS、更低的延遲和更好的可擴展性等。我們可以把L2稱爲“協議層”,而L1和L2之間往往通過跨鏈橋進行連通。
必須要強調,我們構建L2網絡,目的並不僅僅是解決區塊鏈的可擴展性問題,而是因爲分層架構是讓“模塊化區塊鏈”最容易落地的途徑。所謂模塊化區塊鏈,就是將不同類型的問題投放到不同的模塊中去解決。
很多人一直在討論區塊鏈的合規和監管問題,那么我們該如何將比特幣或以太坊納入現有的監管框架中?分層架構也許是解決該問題的一個答案。直接在Layer1層面添加迎合監管要求的業務邏輯,可能會破壞其去中心化和中立性,因此與合規相關的邏輯可以單獨在Layer2上實現。
Layer2可以根據特定的法規或標准來定制,比如建立一個基於許可制的小型區塊鏈,或是狀態通道網絡等東西。這樣即實現了合規性,又不會影響到Layer1的去中心化和中立性。
另外,我們還可以通過分層架構解決安全性和用戶體驗之間的衝突。類比來說,如果你想保證自己的私鑰安全,就要犧牲一定的便捷性,而區塊鏈也是如此,如果你想保證區塊鏈的絕對安全,就要犧牲一些東西,比如該鏈的性能等等。
但如果使用分層架構,我們就可以在L1網絡上完全追求安全性,而在L2網絡上犧牲少許安全性以換取更好的用戶體驗。比如我們可以在L2上使用狀態通道來優化網絡性能,降低延遲。所以說,Layer2的設計無非是安全性和用戶體驗之間的權衡。
上述內容自然而然地就引出了一個問題:是不是任何一條區塊鏈都可以作爲Layer1?
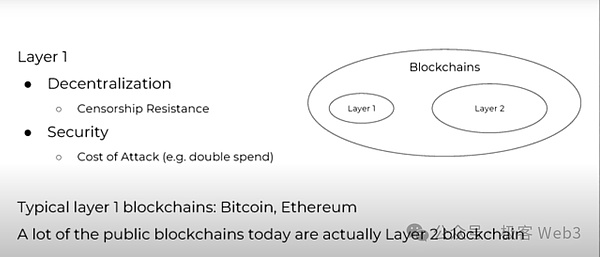
答案是否定的,首先我們必須明確,Layer1網絡的去中心化和安全性高於一切,因爲我們必須通過去中心化來實現抗審查。追求Layer1的安全,究其根本,是因爲L1是整個區塊鏈網絡的根,是整個加密經濟系統的錨。
在這樣的評判標准下,比特幣和以太坊無疑是最經典的L1網絡,它們擁有極強的共識範圍。除這二者之外,大多區塊鏈都不滿足L1的標准,共識程度較低。比如說,EOS的共識就不達標,只能充當一個L2網絡,更何況它的一些規則只適用於其自身。
當前Layer1網絡存在的問題
明確Layer1的定義後,我們要指出,現有的一些L1網絡存在三個問題,這些問題即使在比特幣和以太坊中,也一定程度上存在:

1.數據存儲的公地悲劇問題
我們使用區塊鏈時需要支付一定的費用,但在比特幣的經濟模型中,手續費結構設計中只考慮了計算成本和網絡帶寬成本,沒有成熟地考慮數據存儲成本。
比如用戶向鏈上存儲數據只需要支付一次費用,但存儲期限卻是永久的,所以人們可以濫用存儲資源,將任何東西都永久上鏈,最終網絡裏的全節點要承擔越來越高的存儲成本。這帶來了一個問題:任何節點運行者想參與進該網絡中的成本,都會被最大限度地提升。

假設某區塊鏈的狀態/账戶數據總計超過1TB,則不是每個人都能輕松同步完整的狀態和交易歷史。在這種情況下,就算你能同步到完整的狀態,也很難再去自行驗證對應的交易歷史,這會削弱區塊鏈的免信任性,而免信任恰恰是區塊鏈最核心的價值觀。
以太坊基金會意識到了上述問題,據此在EIP-103中加入了有關存儲租賃制的設計,但是我們認爲這不是最優的解決方案。
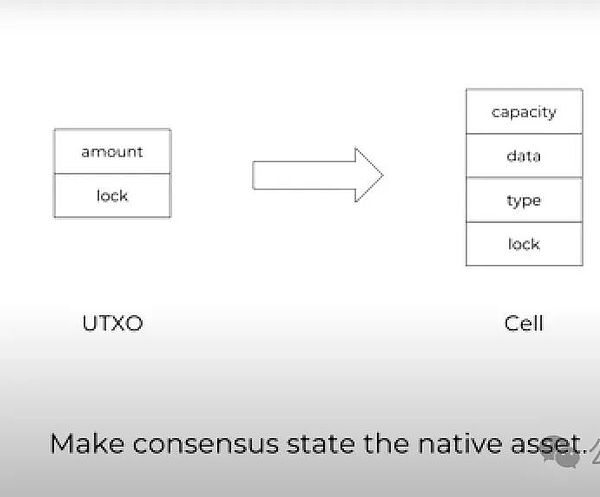
我們在Nervos中提出了全新的狀態模型,稱爲“Cell”,可以看作是UTXO的一種擴展。在比特幣UTXO的狀態中,你能儲存的只有比特幣的余額數值,而Cell中可存儲任意類型的數據,並將比特幣UTXO的amount和integer value泛化爲“Capacity”,用以指定Cell的最大存儲容量。
通過這種方式,我們將CKB上原生資產的數量和狀態大小綁定在一起。任何一個Cell佔據的空間不能超過其容量限制,所以數據總量會保持在一定範圍內。
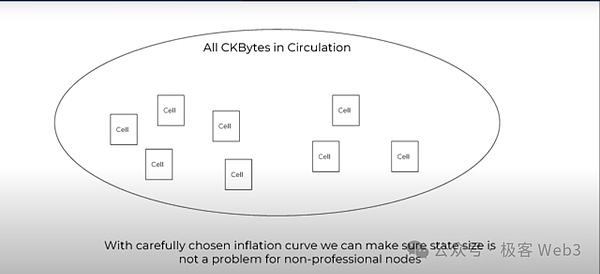
而且我們通過較爲合適的代幣通脹率來確保狀態數據的大小不會對節點運行者造成幹擾。任何人都可以參與到CKB網絡中,他們可以驗證歷史數據,也可以驗證最終的狀態是否有效,這就是CKB針對區塊鏈中存儲問題提出的解決方案。
2.Layer1飢餓問題
如果我們在Layer2上進行擴展,並將大量交易活動放到Layer2上進行,勢必會導致Layer1上的交易數量下降,Layer1礦工/節點運行者的經濟獎勵也會相應降低。這樣的話,Layer1礦工/節點運行者的積極性會下降,最終導致Layer1的安全性下降。這就是所謂的Layer1飢餓問題。
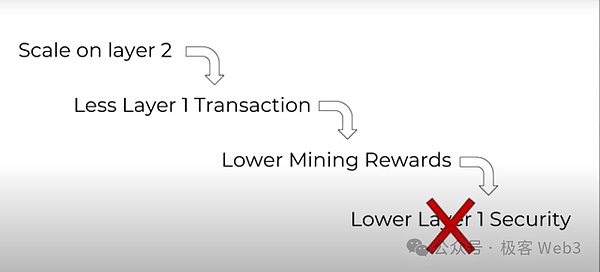
舉個極端的例子,如果我們將所有的交易活動都轉到L2,那么作爲其根基的L1將不可持續。所以如何才能解決這個問題呢?

對此,我們要區分區塊鏈網絡中有哪些種類的用戶,簡單來說可分爲Store of Value Users(SoV user,價值存儲用戶)和Utility Users(應用型用戶)。
仍以CKB爲例,SoV Users將原生資產CKB代幣作爲價值存儲的手段,而Utility Users則利用Cell來存儲狀態。SoV Users對於CKB代幣通脹導致的價格稀釋是排斥的,而Utility User必須向礦工支付狀態存儲費用,該費用與數據存儲的持續時間和佔用空間成正比。
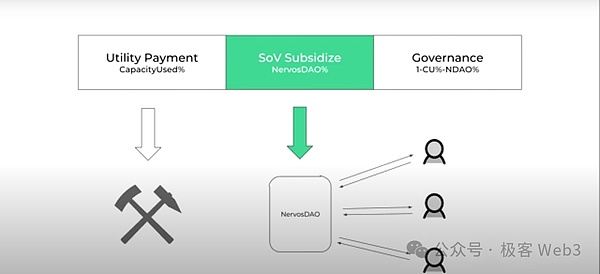
我們會在網絡中持續發行新的CKB代幣以制造固定的通脹率,並將其付給礦工,這就相當於稀釋了Utility Users手中的代幣價值(這就是CKB經濟模型中三種發行模式之一的“二級發行”,該方式每年固定發行13.44億枚CKB代幣,具體內容可以查看《解讀Stable++:RGB++ Layer首個穩定幣協議正式啓航》)。
該過程中SoV用戶的資產同樣被稀釋,因此我們可以給他們一定的補貼抵消通脹損失(這就是後來的NervosDAO分成)。也就是說,礦工從CKB通脹中獲得的收益,實際上只由Utility User來支付。很快我們將發行CKB的代幣經濟論文,相關問題在其中會詳細說明。
基於這樣的代幣經濟學設計,即使CKB鏈上沒有任何交易活動,礦工也能獲得報酬,進而我們可以與任何“價值存儲層”或Layer2兼容。綜上所述,我們通過有意爲之的固定通脹,解決Layer1飢餓問題。
3.加密原語的缺乏
用戶需要不同的加密原語,以使用不同的加密方式或不同的籤名算法,比如Schnorr、BLS等。

想要成爲一條Layer1區塊鏈,必須考慮如何與Layer2進行互操作。以太坊社區中有些人提議使用ZK或Plasma的方式實現Layer2,但是如果沒有ZK相關的原語,你如何在Layer1上完成驗證呢?
另外,Layer1也要考慮與其他Layer1之間的互操作性。仍用以太坊舉例,有人要求以太坊團隊將Blake2b哈希函數預編譯爲EVM兼容的操作碼。該提案的目的是將Zcash和以太坊進行橋接,以便用戶在二者之間交易。上述提案雖然兩年前就已經提出,但直到現在還沒有實現,究其原因即缺乏對應的加密原語,這對Layer1的發展造成了嚴重阻礙。
爲解決該問題,CKB構建了一個抽象程度很高的虛擬機,即CKB-VM,與比特幣虛擬機和EVM截然不同。舉個例子,比特幣有一個專門的OP_CHECKSIG操作碼,用於驗證比特幣交易中的secp256k1籤名。而在CKB-VM中,secp256k1籤名並不需要特殊處理,只需用戶自定義的腳本或智能合約即可進行驗證。
CKB也使用secp256k1作爲其默認的籤名算法,只不過是運行在 CKB-VM 中,而不是作爲硬編碼的加密原語。
CKB構建虛擬機的初衷是,在EVM等其他虛擬機中運行加密原語非常慢,所以要改善這種情況。單個secp256k1籤名在EVM中的驗證耗時大概是9毫秒,而使用相同的算法在CKB-VM計算,耗時僅爲1毫秒,這是將近十倍的效率提升。

所以CKB-VM的價值在於,現在用戶可以在其中自定義加密原語,且絕大多數可以被CKB-VM兼容,因爲CKB-VM採用了RISC-V指令集,任何由GCC(GNU Compiler Collectio,一種廣泛使用的編譯器集合)編譯的語言都可以在CKB上運行。
另外,CKB-VM的高度兼容性也提升了CKB的安全。正如开發者總說的“Don't implement your own version of crypto algorithms, you will always do it wrong”,自行定義加密算法往往會帶來不可預見的安全風險。
總結一下,CKB網絡使用各種方法,解決了我所提出的L1網絡面臨的三種問題,這就是CKB爲什么可以稱爲一個合格的Layer1網絡的原因。
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。