作者:屠敏,CSDN
今年的 5 月宛如夢回 2023 年的 3 月,一場場熱鬧的 AI 盛宴相繼开席。
不過,不知是有意還是無意,去年 3 月,Google 選擇开放大語言模型 PaLM API 之際,幾乎在同一時間 OpenAI 釋出最強模型 GPT-4 驚豔四座,此外僅時隔幾天後,微軟又在一場發布會上官宣自家 Office 全家桶被 GPT-4 革新,導致 Google 似乎成爲被衆人忽視的存在。
些許尷尬的是,今年同樣的情形似乎正在上演,一方面 OpenAI 於昨日凌晨帶來了全面升級的旗艦級 GPT4o 作爲本月 AI 小春晚的开場,另一方面微軟將於下周召开 Bulid 2024,那么,這一次再次遭到夾擊的 Google 能否逆風翻了其兩家“組的局”,我們將從今日凌晨开幕的 I/O 2024 开發者大會中窺見一斑。
今年的 I/O 大會也是 Google 旗幟鮮明地推行“AI First”战略的第八個年頭。
01 亮點搶先看
正如此前所料,在這場時長近 2 小時的 Keynote 上,「AI」是貫穿 I/O 大會全場的關鍵詞,只是沒想到的是,它被提及的次數能高達 121 次,也不難看出 Google 對 AI 的焦慮了。

面對外部來勢洶洶的競爭對手,Google CEO Sundar Pichai(桑達爾·皮查伊)近日在做客一檔節目時表示,「AI 目前還處於發展的早期階段,相信谷歌最終將贏得這場战爭,正如谷歌當初並不是第一家做搜索的公司」。
在 I/O 發布會現場,Sundar Pichai 同樣強調了這一點,「我們仍處於人工智能平台轉變的早期階段。對於創作者、开發者、初創公司和每個人來說,我們看到了巨大的機遇。」
Sundar Pichai 表示,去年發布 Gemini(雙子座)時,它的定位便是多模態的大模型,可以跨文本、圖像、視頻、代碼等進行推理。今年 2 月,Google 發布了 Gemini 1.5 Pro,在長文本方面實現了突破,將上下文窗口長度擴展到 100 萬個 tokens,比任何其他大規模基礎模型都要多。如今,超過 150 萬的开發者在 Google 工具中使用 Gemini 模型。
在發布會上,Sundar Pichi 分享了 Google 內部的最新的進展:
Gemini 應用程序現在已上线 Android 和 iOS 系統。通過 Gemini Advanced,用戶可以訪問 Google 最強大的模型。
Google 將向全球所有开發者推出 Gemini 1.5 Pro 的改進版本。此外,今天擁有 100 萬個 token 上下文的 Gemini 1.5 Pro 現在可以直接在 Gemini Advanced 中供消費者使用,它可以跨 35 種語言使用。
Google 將 Gemini 1.5 Pro 上下文窗口擴展到了 200 萬個 tokens,並以私人預覽版的形式提供給开發人員。
雖然我們還處於 Agent 的早期階段,但是 Google 已經开始先行探索,嘗試了 Project Astra,通過智能手機攝像頭分析世界,識別及解釋代碼、幫助人類尋找眼鏡、還能辨別聲音...
比 Gemini 1.5 Pro 更輕量級的 Gemini 1.5 Flash 發布,針對低延遲和成本等重要的任務進行了優化。
可制作“高質量” 1080p 視頻的 Veo 模型和文本生成圖像模型 Imagen 3 發布;
採用全新架構、27B 大小尺寸的 Gemma 2.0 來了;
Android,第一個包含內置設備基礎模型的移動操作系統,深度集成了 Gemini 模型,成爲以 Google AI 爲核心的操作系統;
第六代 TPU Trillium 發布,與上一代 TPU v5e 相比,每個芯片的計算性能提高了 4.7 倍。
02 Google “殺瘋了”,多款模型齊發
都說做大模型的很“卷”,沒想到在加速趕超的路途中,Google 的“卷”遠超乎想象。在發布會上,Google 不僅對過往的大模型進行了升級,還發布了多款新模型。
Gemini 1.5 Pro 升級更新
去年發布 Gemini(雙子座)時,Google 對它的定位便是多模態的大模型,可以跨文本、圖像、視頻、代碼等進行推理。今年 2 月,Google 發布了 Gemini 1.5 Pro,在長文本方面實現了突破,將上下文窗口長度擴展到 100 萬個 tokens,比任何其他大規模基礎模型都要多。
發布會上,Google 首先對 Gemini 1.5 Pro 一些關鍵用例進行了質量改進,例如翻譯、編碼、推理等,可以處理更廣泛、更復雜的任務。1.5 Pro 現在可以遵循一些復雜和細致的指令,包括指定涉及角色、格式和風格的產品級行爲的指令。也可以讓用戶能夠通過設置系統指令來控制模型行爲。
同時,Google 在 Gemini API 和 Google AI Studio 中添加了音頻理解,因此 1.5 Pro 現在可以對 Google AI Studio 中上傳的視頻的圖像和音頻進行推理。
更值得注意的是,如果說 100 萬 token 的上下文已經足夠長了,就在今天,Google 進一步拓展它的能力,將上下文窗口擴展到 200 萬個 token,並以私人預覽版的形式提供給开發人員,這意味着其朝着無限上下文的最終目標邁出了下一步。

要訪問具有 200 萬 token 上下文窗口的 1.5 Pro,需要加入 Google AI Studio或適用於 Google Cloud 客戶的 Vertex AI 中的候補名單。
更輕量級的新模型 Gemini 1.5 Flash
Gemini 1.5 Flash,這是一款專爲擴展而打造的輕量級型號,也是 API 中速度最快的 Gemini 型號。它針對低延遲和成本最重要的任務進行了優化,服務成本效益更高,並具有突破性的長上下文窗口。

雖然它比 1.5 Pro 模型重量更輕,但能在海量信息中進行多模態推理。默認情況下,Flash 也是具有 100 萬個 token 上下文窗口,這意味着你可以處理一小時的視頻、11 小時的音頻、超過 30,000 行代碼的代碼庫或超過 700,000 個單詞。
Gemini 1.5 Flash 擅長做摘要、聊天、圖像和視頻字幕、從長文檔和表格中提取數據等。這是因爲 1.5 Pro 通過一個名爲“distillation”(蒸餾)的過程對其進行了訓練,將較大模型中最重要的知識和技能轉移到更小、更高效的模型中。
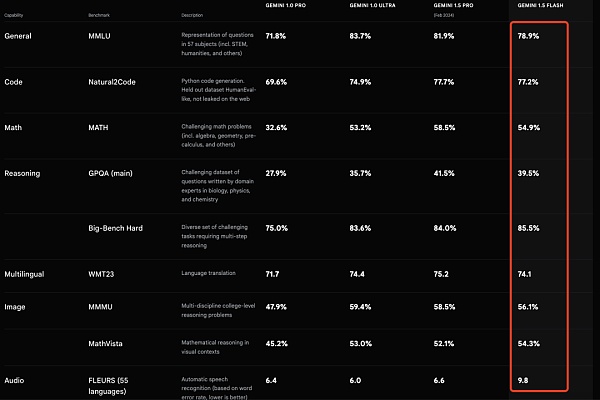
Gemini 1.5 Flash 的價格定爲每 100 萬個token 35 美分,這比 GPT-4o 的每 100 萬個token 5 美元的價格要便宜一些。
Gemini 1.5 Pro 和 1.5 Flash 均已推出公共預覽版,並在 Google AI Studio 和 Vertex AI 中提供。
Google 第一個視覺語言开放模型 PaliGemma 現已推出
PaliGemma 是一個功能強大的开放式 VLM(視覺語言模型),靈感來自 PaLI-3。PaliGemma 基於 SigLIP 視覺模型和 Gemma 語言模型等开放組件構建,旨在在各種視覺語言任務上實現一流的微調性能。這包括圖像和短視頻字幕、視覺問答、理解圖像中的文本、對象檢測和對象分割。
Google 表示,爲了促進开放探索和研究,PaliGemma 可通過各種平台和資源獲得,你可以在 GitHub、Hugging Face 模型、Kaggle、Vertex AI Model Garden 和 ai.nvidia.com(使用 TensoRT-LLM 加速)上找到 PaliGemma,並通過 JAX 和 Hugging Face Transformers 輕松集成。
Gemma 2 發布
全部發布 Gemma 2 將提供新尺寸,並採用專爲突破性性能和效率而設計的全新架構。Gemma 2 具有 270 億個參數,其性能可與 Llama 3 70B 相媲美,但尺寸卻只有 Llama 3 70B 的一半。

據 Google 透露,Gemma 2 的高效設計使其所需的計算量少於同類模型的一半。27B 模型經過優化,可以在 NVIDIA 的 GPU 上運行,也可以在 Vertex AI 中的單個 TPU 主機上高效運行,從而使更廣泛的用戶更易於部署且更具成本效益。

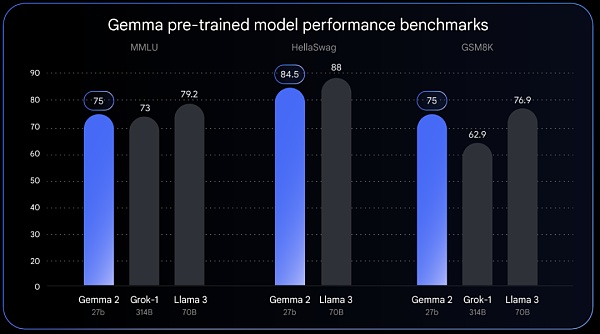
Gemma 2 將於 6 月推出。
Veo:最新、最先進的視頻生成模型
可以視爲對標 OpenAI 的 Sora,Google 在今天推出了視頻生成模型 Veo,它可以生成各種電影和視覺風格的高質量 1080p 分辨率視頻,時間可以超過一分鐘。
Veo 以 Google 多年的生成視頻模型工作爲基礎,包括生成查詢網絡(GQN)、DVD-GAN、Imagen-Video、Phenaki、WALT、VideoPoet 和 Lumiere,結合架構、縮放法則和其他技術來提高質量和輸出分辨率。
從今天开始,用戶可以加入候補名單,申請使用 Veo。
Imagen 3:高質量的文本到圖像模型
與 Google 之前的模型相比,最新發布的 Imagen 3 分散注意力的視覺僞影要少得多,它可以更好地理解自然語言、提示背後的意圖,並融合較長提示中的小細節。

從今天开始,Imagen 3 可供選擇的創作者在 ImageFX 中進行私人預覽,並加入候補名單。Imagen 3 即將推出 Vertex AI。
未來暢想:通用 AI 代理 Project Astra
所謂 Agent,是指具有推理、計劃和記憶能力的智能系統,它們能夠提前“思考”多個步驟,並跨軟件和系統工作。
在今天發布會上,Google DeepMind CEO、聯合創始人 Demis Harbis 透露,Google 內部一直在致力於开發對日常生活有幫助的通用 AI Agent,Project Astra(高級視覺和說話響應代理)便是主要的嘗試之一。
這個項目是在 Gemini 的基礎上,Google 开發了原型代理,可以通過連續編碼視頻幀、將視頻和語音輸入組合到事件時間线中並緩存此信息以進行有效調用,從而更快地處理信息。
通過利用語音模型,Google 還增強了它們的發音,爲代理提供了更廣泛的語調。這些代理可以更好地理解他們所使用的上下文,並在對話中快速做出響應。
在發布會上演示的示例中,通過 Project Astra,可以自動識別出現實場景中發出聲響的東西、甚至可以直接定位到發出聲音的具體部件、也能解釋電腦屏幕上出現代碼的作用、還可以幫助人類找到眼鏡等等。
”有了這樣的技術,我們很容易想象未來人們可以通過手機或眼鏡設備擁有專業的人工智能助手。其中一些功能將於今年晚些時候出現在 Google 產品中“,Google 表示。
03 Gemini Advanced 升級,可定制 Gemini
現如今,改進之後的 Gemini 1.5 Pro 引入了 Gemini Advanced 訂閱中,面向全球所有开發者推出 Gemini 1.5 Pro 的改進版本,它可以跨 35 種語言使用。
如上文所述默認情況下,Gemini 1.5 Pro 擁有 100 萬 token 上下文,這么長的上下文窗口意味着 Gemini Advanced 這可以理解多個大型文檔,預計總共最多 1,500 頁,或總結 100 封電子郵件,處理一小時的視頻內容或超過 30,000 行的代碼庫。
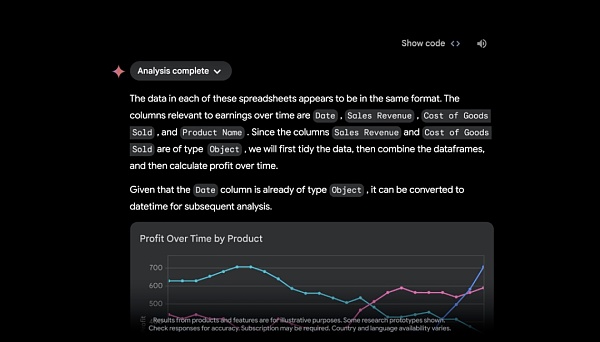
借助 Google Drive 或直接從設備上傳文件的功能,Google 透露,很快,Gemini Advanced 將充當數據分析師,從上傳的數據文件(如電子表格)中發現見解並動態構建自定義可視化和圖表。
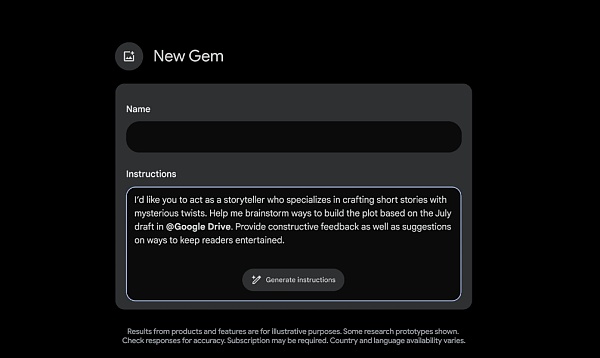
爲了獲得更加個性化的體驗,Gemini Advanced 訂閱者很快就能創建 Gems——Gemini 的定制版本。你可以創建任何你想要創建的 Gem,如健身夥伴、副主廚、編碼夥伴或創意寫作指南。只需描述你希望 Gem 做什么以及你希望它如何響應,例如“你是我的跑步教練,給我一個每日跑步計劃,並保持積極、樂觀和激勵。” Gemini 將接受這些說明,只需單擊一下即可增強它們,以創建滿足特定需求的 Gem。
04 用 AI 改寫 Google 搜索
沒有商業場景的落地應用,大模型技術的迭代似乎只是“紙上談兵”。和 OpenAI 走的路线有所不同,Google、微軟都在 AI 應用賽道上比拼速度。對於搜索起家的 Google 而言,其勢必不會錯過 AI 這波浪潮。
Google 副總裁、搜索主管 Liz Reid 表示,“借助生成式人工智能,搜索可以做的事情超出你的想象。因此,你可以提出任何你想到的事情或任何你需要完成的事情——從研究到計劃再到集思廣益——Google 將負責所有的跑腿工作。”
AI Overviews:「一次搜索,獲得所有信息」
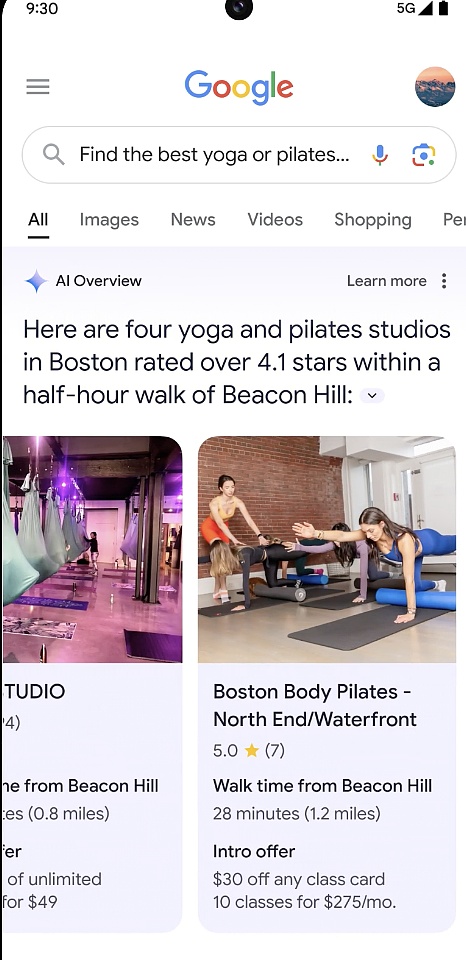
在發布會上,Google 發布了一個名爲“AI 概述”(AI Overviews)的功能,做到「一次搜索,獲得所有信息」。
簡單來看,有時你想要快速得到答案,但沒有時間將所需的所有信息拼湊在一起,如“你正在尋找一家新的瑜伽或普拉提工作室,並且想要一家受當地人歡迎、交通便利且還爲新會員提供折扣的工作室”,你只需說清楚自己的需求進行一次搜索,AI Overviews 會給出解決復雜問題的答案。
拍攝視頻,獲得 AI 幫助
由於視頻理解的進步,Google 也對視覺搜索功能進行了增強。可以通過 Google Lens 視頻搜索,對你遇到的問題或周圍看到的事物(包括運動的物體)進行拍攝,從而進行搜索得到解答,節省用文字描述不清楚造成的時間浪費和麻煩。
不過,以上兩項功能目前僅對美國地區推出,後續會向更多國家推出。
除了在搜索層面,大模型的到來,也將進一步提升產品的智能性。
Ask Photos
在照片搜索應用層面上,Google 帶來了一個“詢問照片”(Ask Photos)功能。
可以借助 Gemini,識別照片不同背景信息,如詢問:自己的女兒什么時候學會遊泳的?遊泳進展如何?照片將所有內容匯總在一起,幫助用戶快速收集信息並解惑。
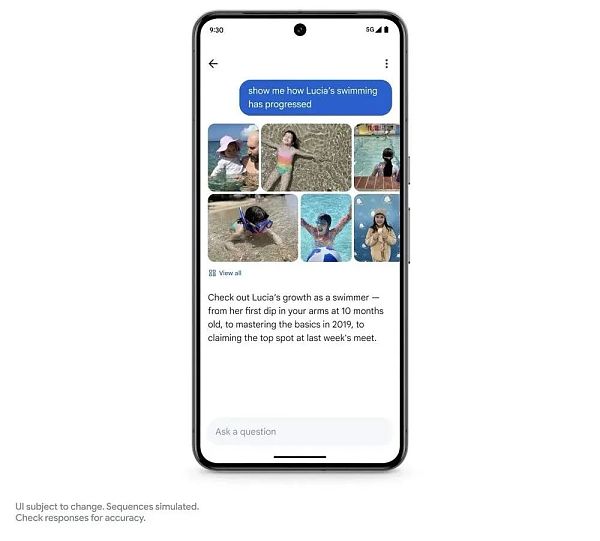
這一項功能目前還沒有上线,Google 稱今年夏季將推出。
Gemini 1.5 Pro 引入到 Google Workspace
Google 還將大模型集成到 Google Workspace,譬如,在 Gmail 中搜索電子郵件,通過與學校最近往來的郵件,隨時了解孩子學校發生的一切情況。我們可以要求 Gemini 總結一下學校最近發來的所有電子郵件。它在後台識別相關電子郵件,甚至分析 PDF 等附件。
新增 NotebookLM 中的音頻輸出
NotebookLM 是 Google 在去年 7 月推出的一款AI 筆記應用 ,可圍繞用戶上傳文檔完成摘要、創建想法。
基於多模態大模型技術,Google 在該應用上新增了音頻輸出功能。它使用 Gemini 1.5 Pro 獲取用戶的源材料並生成個性化的交互式音頻對話。
05 深度集成 Gemini 的 Android
用 AI 對操作系統進行升級,是微軟和 Google 正在大力推進的事情。作爲全球第一大移動操作系統,Android 擁有數十億用戶。Google 對此表示,已將 Gemini 模型整合到 Android 中,並引入了很多實用的 AI 功能。

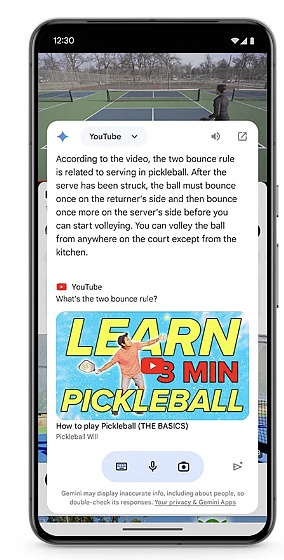
如通過“Circle to Search”(劃圈搜索),可以使用戶無需切換應用程序,使用畫圈、塗鴉、點擊等簡單的交互方式獲取更多信息,如今,Circle to Search 可以幫助學生完成作業,當學生圈出他們遇到的提示時,他們將獲得解決一系列物理和數學問題的分步說明從而獲得更深入的理解,而不僅僅是答案。
另外,Google 將很快在 Android 系統上更新 Gemini,方便用戶在應用程序頂部調出 Gemini 的疊加層,以便以更多方式輕松使用 Gemini。
「Android 是第一個包含內置設備基礎模型的移動操作系統」,借助 Gemini Nano,Android 用戶可以快速體驗 AI 功能。Google 透露,從今年晚些時候的 Pixel 开始,其將推出最新型號 Gemini Nano 與多模態。這意味着新版 Pixel 手機不僅能夠處理文本輸入,還能夠理解更多上下文信息,例如視覺、聲音和口語。
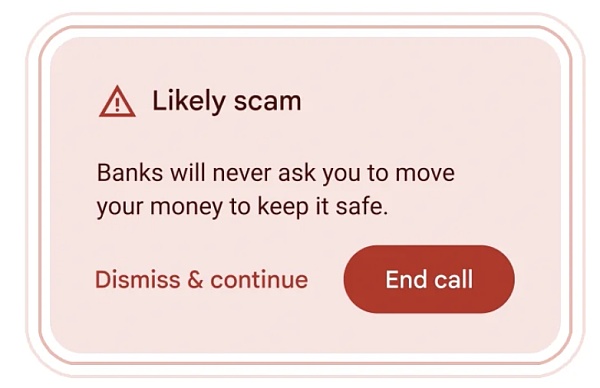
此外,Google 在 Android 中借助 Gemini Nano 在通話過程中檢測到通常與詐騙相關的對話時,提供實時警報,例如,如果有聲稱”銀行“的人要求你緊急轉账、使用禮品卡付款或要求提供卡 PIN 碼或密碼等個人信息(這些都是不常見的銀行要求),你就會收到提醒,不過這項功能還在測試中。
06 第六代 TPU Trillium
Sundar Pichai 表示,訓練最先進的模型需要大量的計算能力。過去六年中,行業對 ML 計算的需求增長了 100 萬倍。並且每年都會增加十倍。
爲了適應 ML 計算的增長需求,其推出了第六代 TPU—— Trillium,與上一代 TPU v5e 相比,每個 Trillium 芯片的計算性能提高了 4.7 倍。爲了達到這種性能水平,Google 擴大了矩陣乘法單元 (MXU)的大小並提高了時鐘速度。
此外,Trillium 還配備了第三代 SparseCore,這是一種專用加速器,用於處理高級排名和推薦工作負載中常見的超大嵌入。Trillium TPU 可以更快地訓練下一波基礎模型,並以更少的延遲和更低的成本爲這些模型提供服務。
Trillium TPU 的能效比 TPU v5e 高出 67% 以上。
據悉,Google 將於 2024 年底向其雲客戶提供 Trillium。
07 安全措施
除了以上模型與產品更新外,Google 在安全方面也有了最新動作,旨在放在 AI 濫用等情況。
一方面,Google 推出了一個基於 Gemini 的新模型系列,並針對學習進行了微調,發布了 LearnLM。其將研究支持的學習科學和學術原則集成到 Google 的產品中,幫助管理認知負荷並適應學習者的目標、需求和動機。

另一方面,爲了讓知識更容易獲取和消化,Google 構建了一種新的實驗工具 Illuminate,它利用 Gemini 1.5 Pro 的長上下文功能將復雜的研究論文轉換爲簡短的音頻對話。Illuminate 可以在幾分鐘內生成由兩個人工智能生成的聲音組成的對話,提供對研究論文中關鍵見解的概述和簡短討論。
最後,Google 採用了 “人工智能輔助紅隊”的技術來主動測試自己的系統是否存在弱點並試圖打破它們,並通過將水印工具 SynthID 擴展爲兩種新模式:文本和視頻,使 AI 生成的內容更易於識別。
08 你如何看待 Google I/O 這場發布會?
以上便是 Google I/O 2024 Keynote 的主要內容,產品非常豐富,不過多數都需要等待。
隨着這一場發布會的結束,不少專家也發表了一些看法。來自 NVIDIA 高級研究經理 Jim Fan 表示:
Google I/O。一些想法:該模型似乎是多模式輸入,但不是多模式輸出。Imagen-3 和 music gen 模型仍作爲獨立組件與雙子座分離。將所有模態輸入/輸出原生合並是不可避免的未來趨勢:
使“使用更像機器人的聲音”、“說話速度提高 2 倍”、“迭代編輯此圖像”和“生成一致的連環畫”等任務成爲可能。
不會丟失跨模態邊界的信息,如情感和背景聲音。
提供新的語境功能。你可以通過少量的示例,教模型以新穎的方式將不同的感官結合起來。
GPT-4o 做得並不完美,但它的形式因素是正確的。用 Andrej 的 LLM-as-OS 比喻:我們需要模型原生支持盡可能多的文件擴展名。
谷歌正在做的一件事是正確的:他們終於在認真努力地將人工智能整合到搜索框中。我感覺到了 Agent 流:規劃、實時瀏覽和多模態輸入,所有這些都來自登錄頁面。谷歌最強大的護城河是分銷。Gemini 不一定要成爲最好的模型,也可以成爲世界上最常用的模型。
AI 著名學者吳恩達表示,“祝賀我所有的 Google 朋友在 I/O 上發布了很酷的公告!我個人期待 Gemini 擁有 200 萬個 token 輸入上下文窗口以及對設備上 AI 的更好支持——應該會爲應用程序構建者帶來新的機會!”
鄭重聲明:本文版權歸原作者所有,轉載文章僅為傳播信息之目的,不構成任何投資建議,如有侵權行為,請第一時間聯絡我們修改或刪除,多謝。